你刚刚降落了一个新的大,长期账户。您需要制定对该行业的正确理解,如何构建,以及领导者所以您可以帮助您的客户发展强有力的关系,并在行业中建立强烈的思维领导。
一种方法发现这些人是通过行业出版物,以策略和行业最佳实践提供内容的领导者。
在本教程中,我们将使用爬行和刮擦来创建此类数据库的核心 – 影响者您可以使用。我将使用python,如果要遵循,可以获得交互式版本,如果要遵循,修改代码,或者以后将其用作模板。
制作它熟悉,行业是在线营销和广告业,该出版物是Semrush博客,爬虫是开源
履带式爬行者。 在这篇文章时,这个博客有393名作者,每个都有个人资料页面。您可以手动复制并粘贴所有的简档和链接,但您的时间比这更有价值。
准备(提取页面和数据元素)
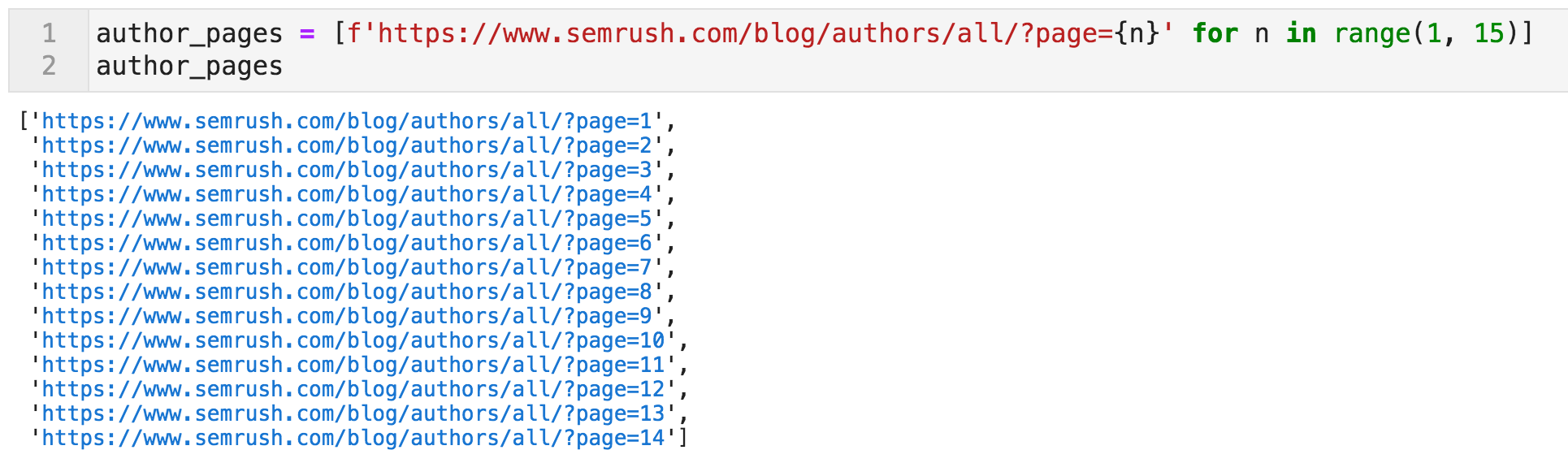
博主列表可以在几页使用此模板上找到每个Blogger的配置文件页面:
https://www.semrush.com/blog/authors/all/?page= {n} – 其中“n”是从一到十四的数字。我们首先通过生成这些页面的列表来开始。将指示履带开始在此开始。
从这些页面中,履带应该遵循使用CSS选择器,链接和每个配置文件页面提取我们感兴趣的某些元素。如果您不熟悉CSS(或XPath)选择器,它们基本上是一种方式,可以以更明显的和特定于“列表项”的语言指定页面的部分,而是以对应的方式我们如何考虑和查看页面。
你最有可能不想要从页面中的所有链接。您通常需要类似于“具有社交媒体图标的页面顶部的所有链接”。我使用一个名为 selectorgadget
的良好浏览器工具来帮助我找到名称选择器。激活它后,在页面的一部分中突出显示任何单击,请与所有类似的元素一起突出显示。如果您想要更具体,可以单击其他元素以取消选择它们。
在下面的示例中,我首先单击LinkedIn图标,该图标还在页面上选择了几个其他链接。然后一旦我点击了主机图标,它就取消了所有其他元素(这就是为什么它现在处于红色 – 请参阅下面的图像),并且我给出了与此特定元素对应的选择器。
页面的底部,您可以看到 .b-social-links__item_ico_linkedin
,它将明确识别这些页面上的LinkedIn链接。您还可以单击XPath按钮以获取等效模式如果需要。所以这就是WE指定爬虫我们想要的元素。与XPath选择器提取页面元素
我对其他元素做了相同,并且它们在下面命名为此{key:value}映射(Python字典)。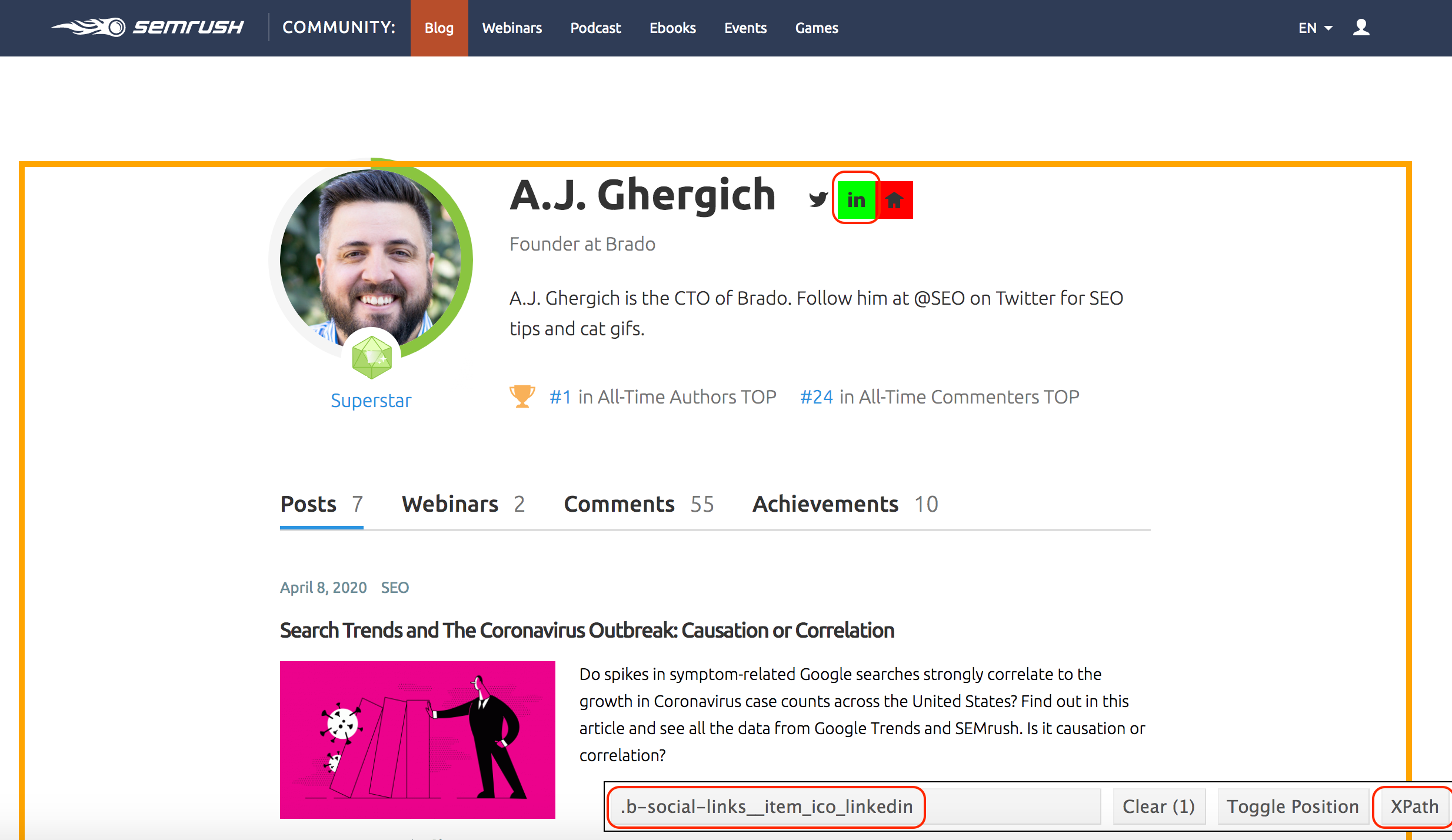 。如果您未指定,则仍将获取正确提取的链接,但您将获取整个链接对象:
。如果您未指定,则仍将获取正确提取的链接,但您将获取整个链接对象:
链接文本
在每种情况下,我们指定了我们是否想要 HREF 或文本
属性
CSS选择:映射到引出图案
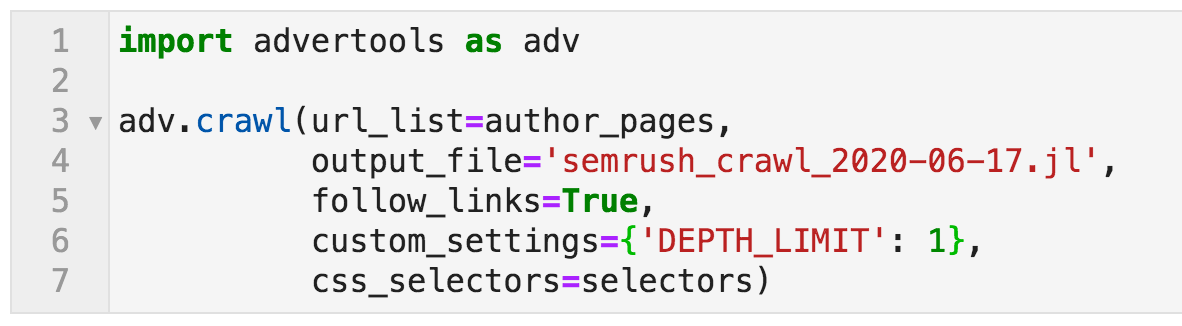
名 所以现在,我们已经准备好了开始页面,我们有要提取的元素。为了爬网,我们使用以下命令: 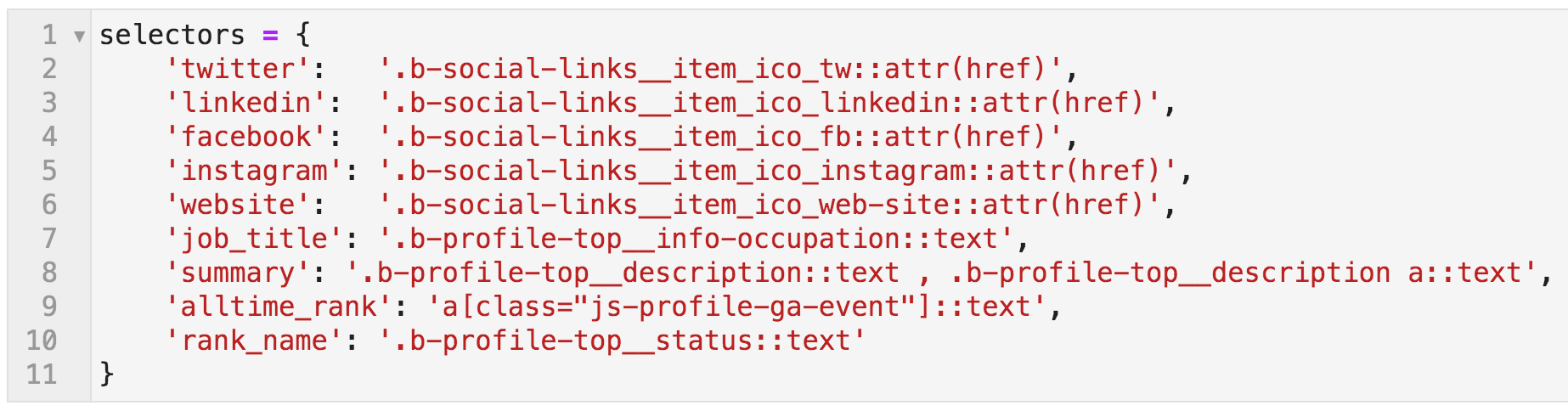
让我解释说:
将授权作为ADV :激活adverools包并使用别名 adj 将其称为速记。 爬网是爬行函数的名称,它需要几个参数来自定义其行为。 url_list = author_pages
:这是爬虫将开始爬行的地方。 author_pages
是我们给LIS的名字包含与博主配置文件链接的十四个URL。 output_file :这是我们希望保存爬网数据的地方。提供描述性名称以及日期总是很好。 “.jl”是为“jsonlines”,这是一个灵活的存储数据方式,其中每个URL的数据将以独立的行保存在文件中。我们将其作为DataFrame导入其中,然后可以保存到CSV格式以便更容易分享。 power_links = true :如果设置为false,则爬网程序只会抓取指定的页面,也称为“列表模式”。在这种情况下,我们希望爬网程序遵循链接。这意味着对于爬出的每个页面,将遵循所有链接。现在我们不想抓取整个网站,所以我们使用以下设置限制我们的爬行。 ‘depth_limit’:1  。这需要几分钟,现在我们可以使用熊猫函数打开文件 Read_json
。这需要几分钟,现在我们可以使用熊猫函数打开文件 Read_json
,并通过指定
行= true (因为它是jsonlines)。
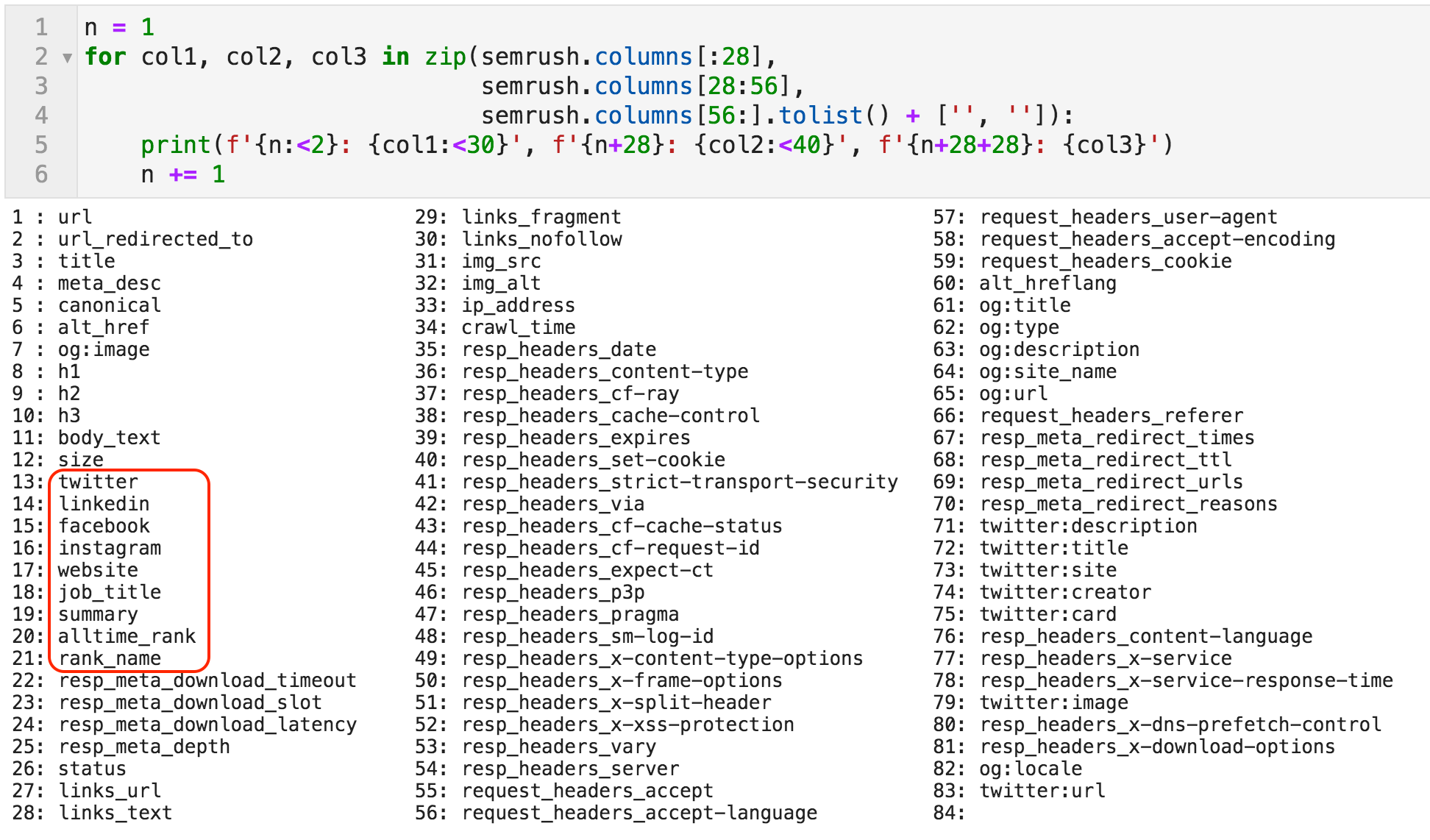
现在我们已定义变量
SEMRUSH 引用爬网DataFrame。让我们找到rst看看它包含的列。正如您所看到的,有八十三列。大多数是固定的,这意味着它们将始终存在于任何爬网文件中(如“标题”,“H1”,“Meta_desc”等),有些是动态的。 例如,OpenGraph数据可能存在于页面上,可能不会,因此仅在页面上显示某些列。如果我们在该示例中明确地指定它们,则只会出现具有社交网络名称和我们指定的名称的列。
图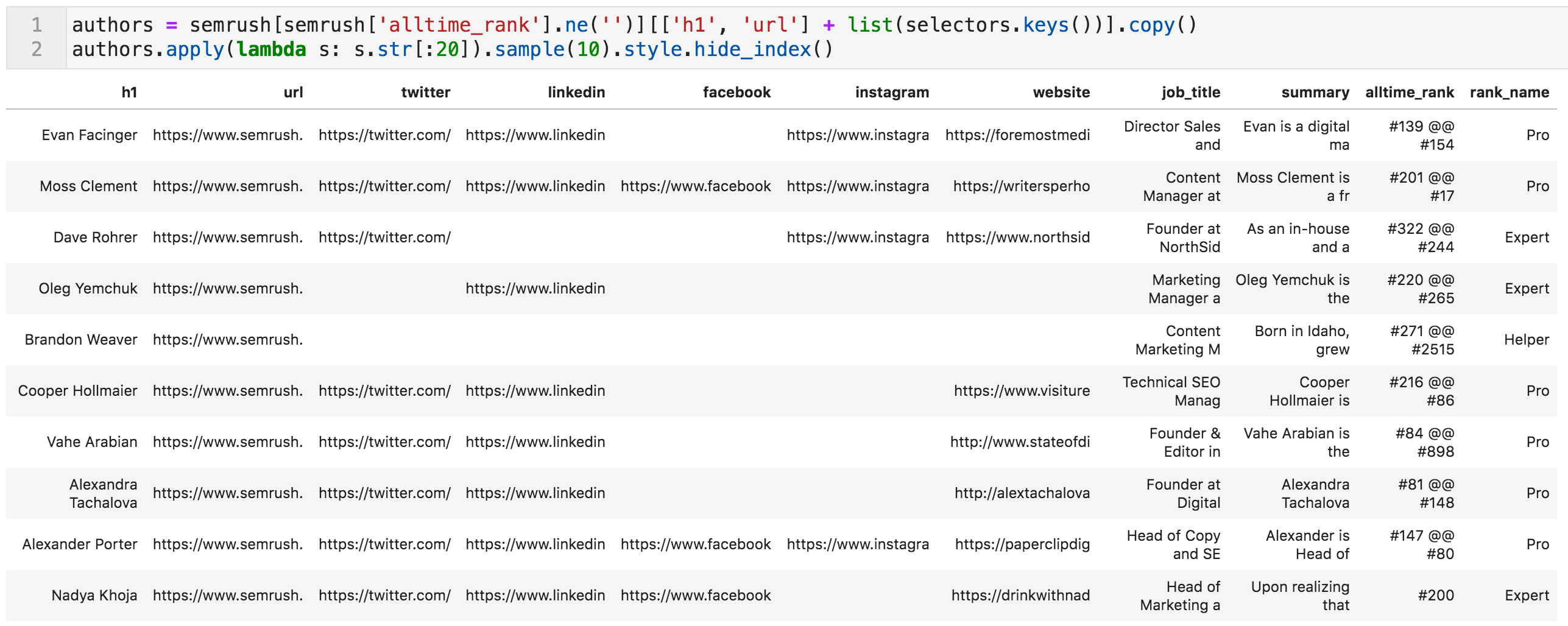
因为这不是SEO审计,我们只对提取物感兴趣与作者有关的数据;我们现在将创建数据的子集。它基本上说了我们想要
semrush
的子集(称为
作者),其中列的小区 Alltime_rank
不是空的,并且列是“H1”的地方,“ URL”,或任何我们提取指定的键。
中的作者表的随机样品(截短以适合筛选的值)
![]()
我们几乎完成了。需要一些清洁数据。
清理数据 您可能已经注意到 Alltime_Rank 列中的附加字符,以及它包含的事实两个值;一个用于职位的排名,另一个用于评论中的等级。下面的代码分割两个值并去除噪声的字符。
![]()
Çode从“alltime_rank”中删除不必要的字符
现在我们可以为每个等级创建一个单独的列,并确保它们是整数所以我们可以排序由这些列。在某些情况下,博主并没有征求意见的等级,我们给他们的零等级。
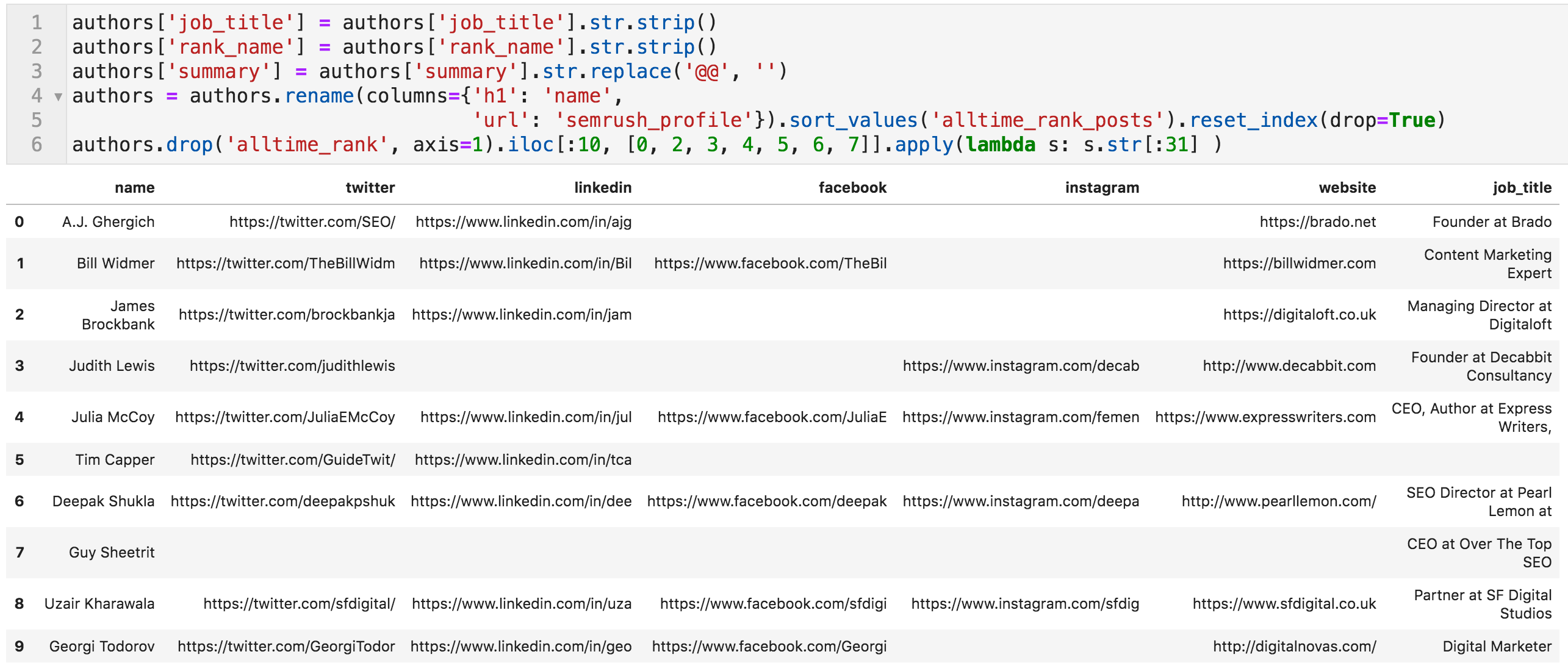
一个最后的步骤。列作业和 rank_name 在开头和结束时包含一些空格,因此我们将删除它。我们还删除了摘要列中出现的分隔符,这些列是两个@字符“@@@”。
的代码,使最终的编辑,并且顶部10的博客(值截断以适应在屏幕上)
让我们快速检查工作似乎是否正确。让我们看看有多少行和列在
作者
:
获取DataFrame的形状(行数和列数) 388和13列。他们不是393? 这是真的。似乎有五个博主有具有相同数据但在不同的设计中具有相同的特殊配置文件页面(不同的CSS选择器)。这些是博客的“专栏作者”。我手动提取了他们的数据并将它们添加到表中,您可以在最终 semrush_blog_authors.csv文件中看到。 一个非常乐观的人曾经在地板上找到了一个马蹄铁,立即想到,“哦,现在我只需要三个马蹄铁和一匹马!” 这个名单只是一个马蹄。马是实际与那些人交谈的过程,建立真正的关系,找到一种有意义的方式来贡献网络。现在你有一个所有推特帐户的列表,您可能希望创建一个列表以跟踪您发现有趣的人。您可能只对一个子集感兴趣,因此您可以通过包含包含“C的配置文件的标题或摘要来过滤”C“,”SEO“,”付费“,或者你感兴趣的东西。考虑创建或加入专业团体并邀请人们邀请人。 祝你好运!
