大约一年一次,我们为自己设定了一个目标。
这个目标是为客户建立最大,最快的更新,最高质量的反向链接数据库,比市场上的领先知名竞争对手更好。
现在我们达到了我们的目标,我们不能等你自己测试它!
你想知道如何,我们能够建立这样的数据库吗?
我们投资于基础设施,将30,000小时的工作组合在我们的工程师和数据科学家,500多台服务器,约16,722杯咖啡中。
听起来很简单,不是吗?

只是检查出这篇博客文章,看看如何我们现在更快。
新的和改进的反向链接数据库
fi让我们谈谈新的东西,然后我们将向您展示我们如何实现它以及我们解决的问题。
随着存储增加的增加和更多爬行器和我们的反向链接数据库的三倍具有查找,索引和增长的容量。
平均来,我们现在已经爬行:

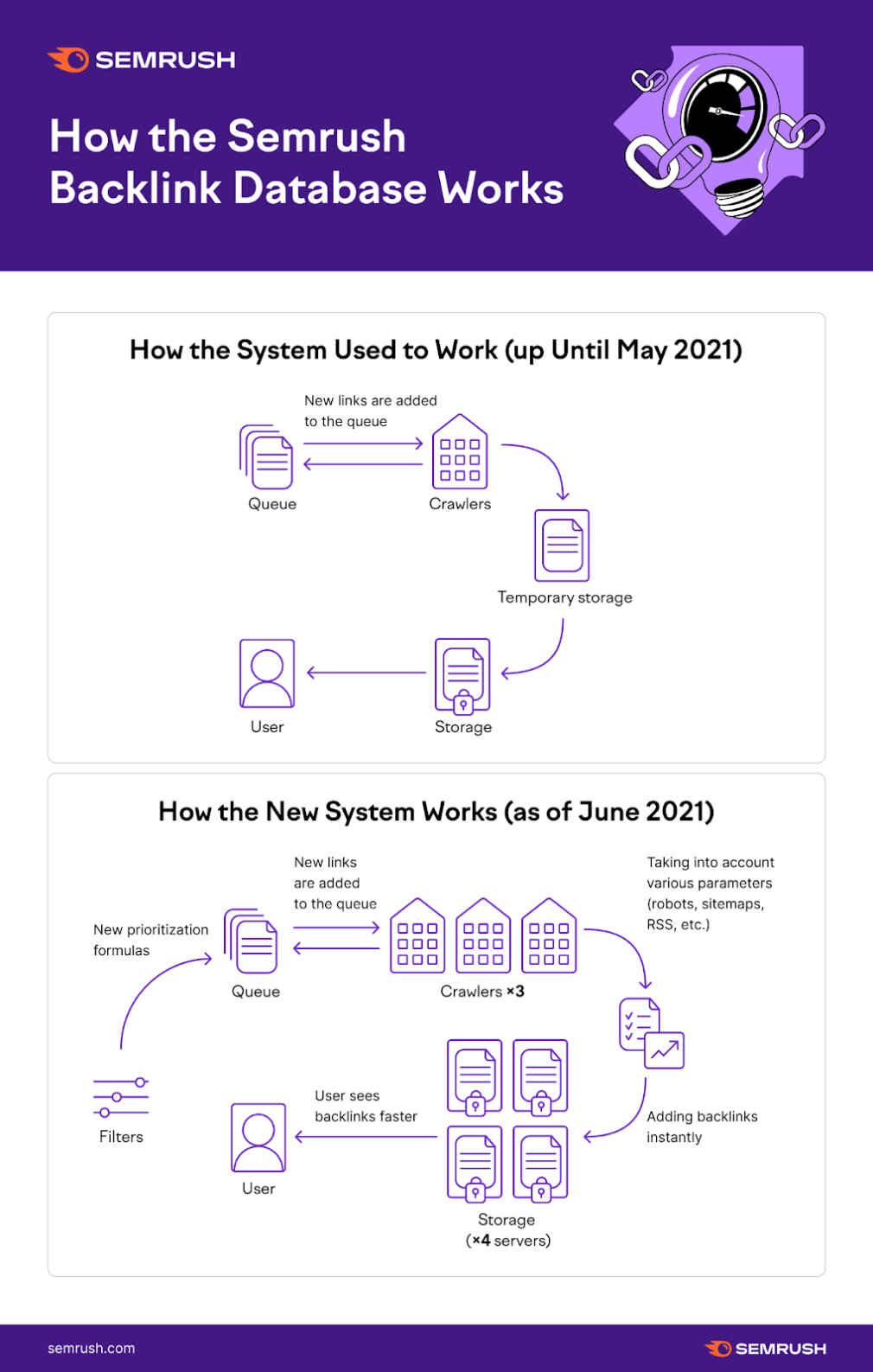 首先,我们生成一个URL的队列,该网址决定将提交哪些页面以便爬行。
首先,我们生成一个URL的队列,该网址决定将提交哪些页面以便爬行。 那么我们的爬行者出去检查这些页面。当我们的爬网程序识别从这些页面指向Internet上的另一页页面的超链接时,它们保存该信息。
.[接下来,将有一个临时存储,它在将所有SEMRUSH用户在工具中看到的公开存储空间之前,将所有这些数据保持一段时间。
通过我们的新版本,我们几乎删除了临时存储步骤,添加了3x更多的爬虫,并在队列之前添加了一组过滤器,因此整个过程更快,更高效。
简单地说,有太多页面在互联网上爬行。
有些需要经常爬行,有些人不必爬行。因此,我们使用队列决定在爬行中提交订单URL。
这个步骤中的一个常见问题正在爬行太多类似,无关的URL,这可能导致人们看到更多垃圾邮件和更少的唯一参考域。
我们做了什么?
优化队列,我们添加了优先考虑唯一内容,更高权限网站的过滤器,并防止链接服务器场。因此,系统现在查找更唯一的内容,并使用重复链接生成更少的报告。
它现在如何运行的一些亮点: 要保护我们的队列免受链接场,我们检查大量域是否来自同一IP地址。如果我们看到来自同一IP的太多域,他们将在队列中的优先级降低,允许我们从不同的IPS爬网,而不会卡在链接场上。要保护网站并避免使用类似的链接污染我们的报告,我们检查s中是否有太多的URLame域名。如果我们在同一域看到太多的URL,他们将并不一天将爬行。要确保尽快爬网新页面,我们之前没有爬出的任何网址将更优先。每个页面都有自己的哈希码,有助于我们优先考虑爬行唯一内容。我们考虑了在源页面上生成的新链接的频率。我们考虑了网页和域的权限分数。
队列如何改进:
10+滤除不必要的链路的不同因素。由于质量控制的新算法,更独特和高质量的页面。
爬虫
我们的爬虫在互联网上遵循内部和外部链接,以搜索带有链接的新页面。因此,如果有传入链路T,我们只能找到页面o它。
在审查我们以前的系统时,我们看到有机会提高整体爬行能力并找到更好的内容 – 网站所有者希望我们爬行和指数的内容。
我们做了什么?
推翻了我们的爬行者数量(从10到30)。使用不会影响页面内容(&sessionID,UTM等)的URL参数停止爬行页面。增加次数频率和遵守robots.txt文件网站上的指令。
如何改进爬行器:更好的爬行器(现在是30!)在没有垃圾或重复链接的情况下清洁数据,在找到每天的最相关的内容爬网速度存储存储是我们保存您可以看到的所有链接作为SemRush用户的位置。这存储显示工具中的链接,并提供您可以申请的过滤器以查找您要查找的内容。  我们与旧存储系统的主要关注点是它只能在更新时完全重写。这意味着每2-3周,它被重写,进程会重新开始。
我们与旧存储系统的主要关注点是它只能在更新时完全重写。这意味着每2-3周,它被重写,进程会重新开始。
因此,在更新期间,在中间存储中累积的新链路,在刀具中创建了对用户的可见性的延迟。我们想看看我们是否可以提高这一步骤的速度。 我们做了什么? 改善这一点,我们从头开始重写架构。为消除对临时存储的需求,我们将服务器数量增加了四倍以上。 这花了超过30,000小时的工程时间到IM限制最新技术。现在,我们有一个可扩展的系统,无法在现在或将来达到任何限制。 如何改进存储: 500+总服务器287TB RAM存储器16,128 CPU核心30 PB总存储空间闪电快速滤波和报告即时更新 – 不再临时存储反向链路数据库研究 我们在两个部分中运行了一项研究,将我们的反向解分析到Moz,Ahrefs和Majestic的速度进行比较。 与市场上的其他SEO工具相比,我们的工具运行的速度恰到要快得多,请阅读此博客文章。 我们为我们的新反线链接分析数据库感到骄傲,我们希望大家能够体验到它所提供的所有内容。 仅通过注册免费的semru获得免费访问SH帐户和反向链接分析部分将完全向您打开。 试试看,让我们知道你的想法! 欢迎来到动态反向控制管理的未来! SEMRUSH反向解分析 立即免费访问→ 立即免费访问→
