SEMRUSH反向链接更新2021:我们如何构建一个新的反向链接工具
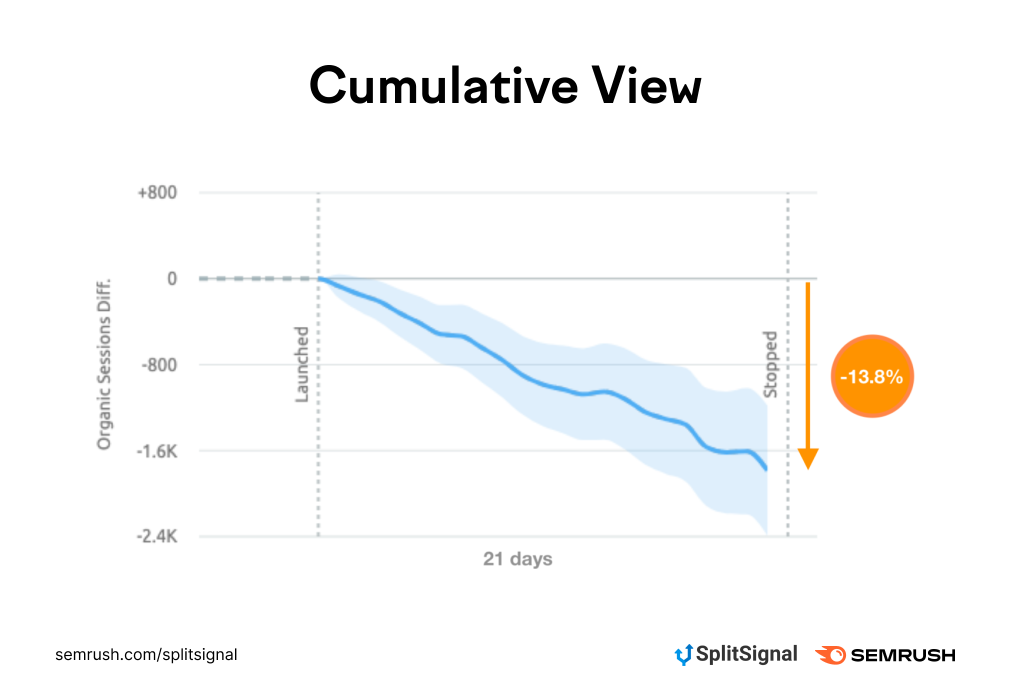
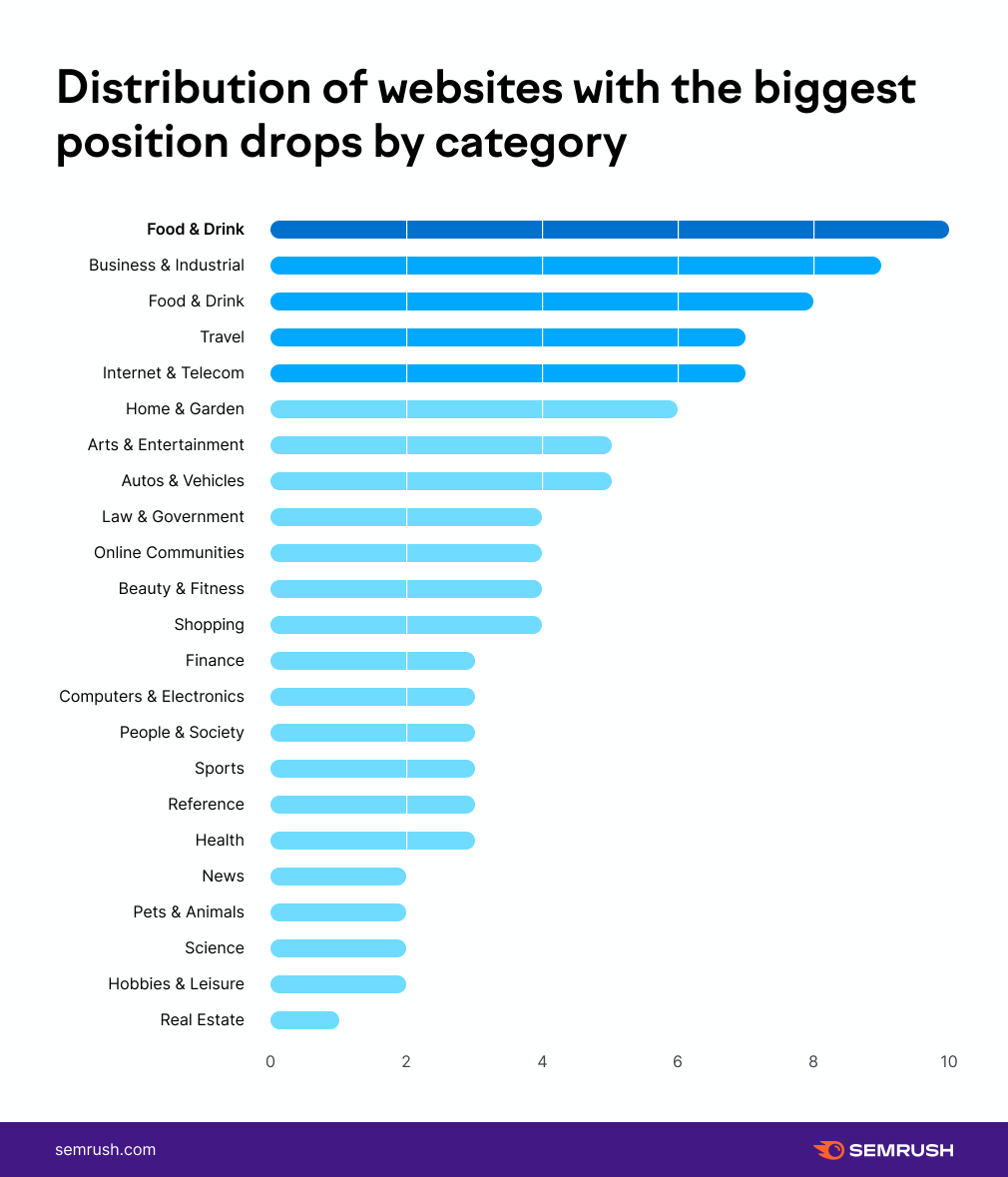
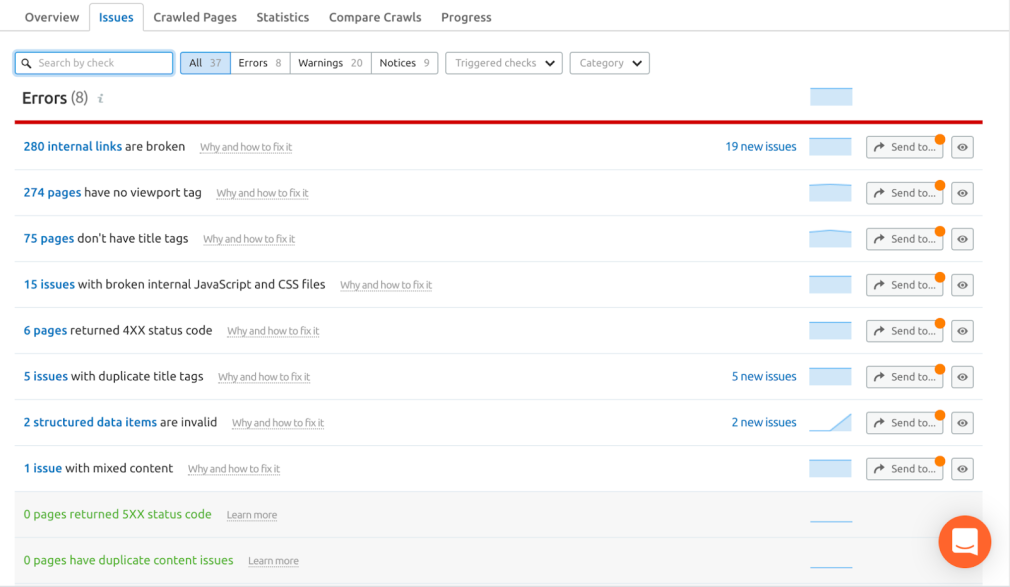
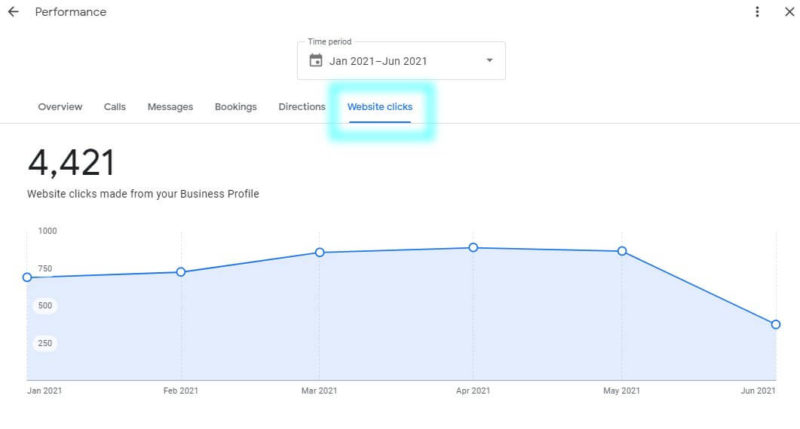
大约一年一次,我们为自己设定了一个目标。 这个目标是为客户建立最大,最快的更新,最高质量的反向链接数据库,比市场上的领先知名竞争对手更好。 现在我们达到了我们的目标,我们不能等你自己测试它! 你想知道如何,我们能够建立这样的数据库吗? 我们投资于基础设施,将30,000小时的工作组合在我们的工程师和数据科学家,500多台服务器,约16,722杯咖啡中。 听起来很简单,不是吗? 只是检查出这篇博客文章,看看如何我们现在更快。 新的和改进的反向链接数据库 fi让我们谈谈新的东西,然后我们将向您展示我们如何实现它以及我们解决的问题。 随着存储增加的增加和更多爬行器和我们的反向链接数据库的三倍具有查找,索引和增长的容量。 平均来,我们现在已经爬行: 如何如何我们深入深入进入有所改进,让我们扫过我们的反向链接数据库如何运行的基础知识。 首先,我们生成一个URL的队列,该网址决定将提交哪些页面以便爬行。 那么我们的爬行者出去检查这些页面。当我们的爬网程序识别从这些页面指向Internet上的另一页页面的超链接时,它们保存该信息。 .[接下来,将有一个临时存储,它在将所有SEMRUSH用户在工具中看到的公开存储空间之前,将所有这些数据保持一段时间。 通过我们的新版本,我们几乎删除了临时存储步骤,添加了3x更多的爬虫,并在队列之前添加了一组过滤器,因此整个过程更快,更高效。 简单地说,有太多页面在互联网上爬行。 有些需要经常爬行,有些人不必爬行。因此,我们使用队列决定在爬行中提交订单URL。…