谷歌多任务统一模型(MUM)是一种回答没有直接答案的复杂问题的新技术。谷歌发布了研究论文,可以提供妈妈AI的线索以及它的工作原理。
妈妈可能由多种创新组成。例如,Google研究论文
超手人变压器:朝着多个任务的单个模型描述了在多任务学习中的新技术,可以成为妈妈的一部分。
虽然这篇文章侧重于两篇本特别有趣的论文,但这并不意味着这些是谷歌的多任务统一模型(MUM)可能是唯一可能是两个技术。
研究论文中描述的Google算法和专利
谷歌通常没有T确认是否使用研究论文或专利中描述的算法。
谷歌尚未确认多任务统一模型(MUM)技术是什么。
多任务统一模型研究论文
有时,与
神经匹配
一样,没有研究论文或专利明确地使用技术的名称。它好像谷歌发明了一组算法一起工作的描述性品牌。
下面的广告联网读数读取这是多任务统一模型(MUM)的情况。没有专利或研究论文完全是妈妈品牌名称。但是……
关于MUM解决
的问题的背景,长形式问题是一个复杂的搜索查询,不能用链路或片段回答。答案需要包含多个副主题的信息段落。
谷歌的妈妈公告描述了某些问题的复杂性与想要了解如何在秋季徒步下徒步旅行富士山的搜索者的示例。
这是Google的复杂搜索查询的示例: “今天,谷歌可以帮助您解决这个问题,但它需要许多思想地考虑的搜索 – 你必须搜索每座山的高度,平均温度下降,徒步旅行的难度,右齿轮使用等等。“
这是一个lon的一个例子G表格问题:
“”湖泊,河流和海洋等水体之间的差异是什么?“
上述问题需要多个段落讨论湖泊,河流和海洋的品质,加上每个水体之间的比较彼此。
这里是答案的复杂性的一个例子:
湖通常被称为静水,因为它没有流动。河流流动。湖泊和河流一般都是淡水。但是一条河和湖有时可以是咸水(咸)。大洋可以深入。
回答长表格问题需要一个由多个步骤组成的复杂答案,例如谷歌分享了关于询问如何准备寄往富士山e秋天。
谷歌的妈妈公告没有提到长期的问题回答,但问题妈妈的解决似乎是完全的。
(引文:
谷歌研究论文揭示了一个在搜索中的缺点
)。 改变问题如何回答
在2021年5月,一个名叫Donald Metzler的谷歌研究员发表了一篇论文,呈现了搜索引擎如何回答问题所需的情况为了提出一个新的方向,以便给出复杂问题的答案。
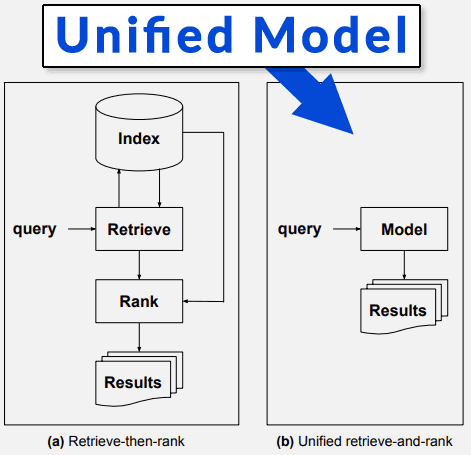
本文指出,当前的信息检索方法,由索引网页和排名组成的信息检索是不充分的,用于回答复杂的搜索查询。
[本文有权题为重新思考搜索:从稀释剂中制作专家(
)
德莱特丹是一个具有肤浅知识的人,就像业余爱好者而不是专家。 纸张定位今天的搜索引擎的状态:
“今天的最先进的系统通常依赖于基于术语的组合…和语义……检索来生成一组初始的候选者。
这组候选者通常通过进入重新排名模型的一个或多个阶段,这很可能是基于神经网络的学习到级模型。
如前所述,索引 – 检索 – 然后排名范例已被停用时间验证,毫无疑问,先进的机器学习和基于NLP的方法是现代系统的索引,检索和排名组件的组成部分。“
基于模型的信息检索
新系统,将专家从稀释剂
研究论文描述是一个与指数检索的人-Rank部分算法。
下面的广告联网读数读数下面的研究论文的参考IR,这意味着
信息检索
,这是搜索引擎所做的。
这里是如何描述搜索引擎的新方向的方式:
“”“”的方法,称为模型的信息检索,旨在取代长寿的通过将传统IR系统的索引,检索和排序组件折叠到单个统一模型中的索引关于“
统一模型如何
”的作品。
让我们在这里停止提醒地提醒谷歌的新算法的名称是多阵列
统一模型
我将跳过
统一模型
的描述,现在并注意到这一点:
“”今天和设想的系统之间的重要区别系统是统一模型替换索引,检索和排名组件。实质上,它被称为基于模型,因为只有模型。“
屏幕截图显示统一模型是什么
在另一个地方稀释剂研究论文状态:
读取下方
“实现这一点,所以被配置基于模型的信息检索框架,通过编码替换索引,检索和排序组件的统一模型
中包含的语料库中包含的知识,从传统的索引检索 – 排名范式中断传统系统。
是否符合谷歌的回答复杂问题的技术称为多任务统一模型和该系统在本5月2021篇论文中讨论的系统是需要的“
统一模型
”用于回答复杂问题?
妈妈研究论文是什么?
r
赛跑搜索:让专家脱离稀释剂
“研究论文列出了Donald Metzler作为作者。它宣布需要完成TAS的算法k回答复杂问题并提出了实现这一目标的统一模型。 它概述了该过程,但细节和实验有点简短。
还有另一篇研究论文2020年12月2020年12月描述了具有实验和细节的算法,其中一位作者是…
唐纳德·梅尔兹勒
。
广告联网读数下面
12020年12月份研究论文的名称是
用户活动流的顺序专家的多任务混合
5月2021年5月重新思考搜索:从稀释剂纸上制作专家概述了一个
统一模型的需要。 E.从12月202020(同一作者)的Arlier研究论文称为多任务
用户活动流的顺序专家的混合物(
)。
这些巧合吗?也许不会。妈妈与另一研究纸之间的相似性是不识别的。
MOSE:用户活性物流的顺序专家的多任务混合物
T1; DR MOSE是从多个数据源(搜索和浏览日志)学习的机器智能技术,以预测复杂的多步骤搜索模式。它是高效的,这使它可扩展且功能强大。那些MOSE的特征匹配莫氏算法的某些品质,特别是莫梅可以回答复杂的搜索查询,并且比它更强大1,000倍像BERT这样的技术。下面的广告联交线读数是什么机器人作用
tl; DR MOSE从用户点击和浏览数据的顺序学习。此信息允许它模拟复杂搜索查询的过程以产生令人满意的答案。
来自谷歌的12月2020 Mose研究论文描述了以顺序顺序建模用户行为,而不是在搜索查询和上下文上建模。
以顺序建模用户行为就像研究用户如何为此搜索,那么这是为了理解如何应答复杂查询。
本文描述它如下:
“在这项工作中,我们研究了如何模拟顺序用户行为的挑战性问题神经多任务学习设置。
我们的主要贡献是一种新颖的框架,顺序专家的混合(MOSE)。它明确地使用专业技术的多栅极混合 – 专家多任务建模框架中的长短期存储器(LSTM)模拟顺序用户行为。“
最后一部分“
多栅极混合 – 专家的多任务建模框架
”是一口。
这是对多种任务/目标优化的算法的参考,这几乎是现在需要知道的一切。 (
引文:使用多栅极混合 – 专家的多任务学习中的任务关系建模的任务关系
)
广告联系读数以下
讨论其他类似的多 – 摊阵算法针对多个目标进行优化的MS,例如同时预测用户可能想要在YouTube上观看的视频,这是一种视频将使更多的参与率,并且哪些视频将产生更多的用户满意度。这是三个任务/目标。
纸评论:
“特别是当任务密切相关时,多任务学习是有效的。”
MOSE在
搜索
,MOSE算法侧重于学习它所谓的
异构数据
,这意味着不同/不同形式的数据。在妈妈的背景下,我们感兴趣的是,在搜索的背景下讨论了MOSE算法,并在搜索者的追求中追求答案,即搜索者找到A的步骤NSWER。“在这项工作中,我们专注于从异构数据源(例如,搜索日志和浏览日志)和它们之间的交互建模用户活动流。” 研究人员在G套件和Gmail中搜索和测试了关于搜索任务的MOSE算法。
下面
MOSE和搜索行为预测 另一个特征,使MOSE成为有趣的候选者与妈妈相关的是它可以预测一系列连续的搜索和行为。 复杂的搜索查询,如Google Mum公告所指出的,最多可能需要八次搜索。
但是如果是算法可以预测这些搜索并将这些搜索结合到答案中,算法可以更好地回答这些复杂的任务离子。 妈妈公告说明:
“但是,通过一种名为MULTITAST统一模型的新技术,我们越来越近于帮助您随着这些类型的复杂需求。所以在未来,您需要更少的搜索来完成完成的事情。“ 和这里是MOSE研究论文状态: 例如,例如,搜索系统中的用户行为流,例如用户搜索日志,是自然的时间序列。建模用户顺序行为作为显式顺序表示可以赋予多项任务模型来包含时间依赖性,从而更准确地预测未来的用户行为。“ 读数的广告联接读数,供资源成本高效 MOSE的效率 算法较少的计算资源需要完成任务,这可以在这些任务中更强大,因为这使其更加缩放了空间。妈妈据说是1,000时间比bert更强大。 MOSE研究论文提到平衡搜索质量与“资源成本,”资源成本是对计算资源的引用。 理想是具有高质量的结果,具有最小计算资源成本,这将允许其扩展为更大的任务。 原始企鹅算法只能在整个Web的地图上运行(称为链接图)一年几次。据推测,这是因为它是资源密集的,不能每天运行。 2016年企鹅变得更加强大,因为它现在可以实时运行。这是为什么产生高质量结果,以最小的资源成本产生高质量结果。读数下方较少的资源成本较少的资源需求需要更强大且可扩展。 这是研究人员所说的关于MOSE的资源成本: “在实验中,我们在两者上显示了MOSE架构在七个替代架构上的效果G套件中的合成和嘈杂的真实世界用户数据。 我们还展示了MOSE架构在Gmail中的真实决策引擎中的有效性和灵活性,涉及数百万用户,在搜索质量之间平衡资源成本。“ [然后朝向纸的末端报告了这些显着的结果: “”我们强调了两种益处。首先,性能明智,MOSE明显优于大量调整的共享底部模型。在需求80%的资源节省时,MOSE能够保留大约8%的文件搜索点击,这在产品中非常重要。 也是由于其不同的资源节省水平跨越不同的资源节省水平建模能力,即使我们在训练期间为任务分配了相同的权重。 广告联接术读数下方以及透明的动力和枢转改变的灵活性,它吹嘘: “当业务需求在实践中保持不变时,这使得能够更具灵活性一种更强大的模型,如MOSE可以减轻重新训练模型的需要,与训练期间的重要性更敏感的模型相比。“ 妈妈,摩西和变压器 揭示了妈妈使用变压器技术建造。 谷歌的公告指出: “”妈妈有可能改变谷歌如何帮助您复杂任务。就像伯特一样,妈妈建立在变压器架构上,但它的功能更强大。 但是,在2020年测试的MOSE版本未使用变压器架构构建。研究人员注意到,MOSE可以轻松 exte 与变压器。 研究人员(在2020年12月发布的文件中)提到的变压器作为一种改变的未来方向: “”用更先进的技术进行实验如变压器被认为是未来的工作。 ……一种由一般构建块组成的系统,可以很容易地扩展,例如使用其他顺序建模单元,除了LSTM之外,包括GRUS,关注和变压器…… 根据研究论文,广告联系读数根据研究论文,通过使用其他架构,可以容易地增压,例如变压器。这意味着MOSE可能是谷歌被宣布为妈妈的一部分。为什么MOSE的成功是值得注意的 谷歌发表了许多算法专利和研究论文。嘛它们的纽约正在推动现有技术的边缘,同时还注意到需要进一步研究的缺陷和错误。 这不是伴娘的情况。这相反。研究人员注意到MOSE的成就以及仍然有机会使其更好。 是什么使得MOSE研究更加值得注意,然后是它声称的成功水平和它留下的门开放更好。 这是值得注意的,当研究论文声称成功而不是成功和损失的混合时是值得注意的。 当研究人员要求在没有重要资源的情况下实现这些成功时,这尤其如此水平。下面的广告联系读数是Google Mum AI技术的影响?妈妈被描述为aRtapy Intelligence Technology。 MOSE被归类为Google的AI博客上的机器智能。 AI和机器智能之间有什么区别?不是很多,他们几乎在同一类别中(请注意,我写了机器智能,而不是机器学习)。谷歌AI出版物数据库根据机智类别根据人工智能对研究论文进行分类。没有人工智能类别。我们不能确定,MOSE是谷歌的妈妈底层技术的一部分。妈妈可能是一部分在一起的技术,而且那个MOSE是一部分其中可能是MOSE是Google Mum的主要部分.Oor可能是MOSE与妈妈无论如何都无关。尽管如此,MOSE是一种成功的方法来预测用户搜索行为的成功方法,并且可以使用变换器轻松缩放它。这是谷歌妈妈技术的一部分,这些论文中描述的算法显示信息检索中最先进的状态是什么。下面护文 使用序列专家对使用者活性流的多任务混合物 (PDF) 重新思考搜索:再思考搜索:从稀释剂的专家 (PDF) 妈妈:用于了解信息的新AI里程碑
