欢迎回到另一周的怪人。
所以,让我们进入它。
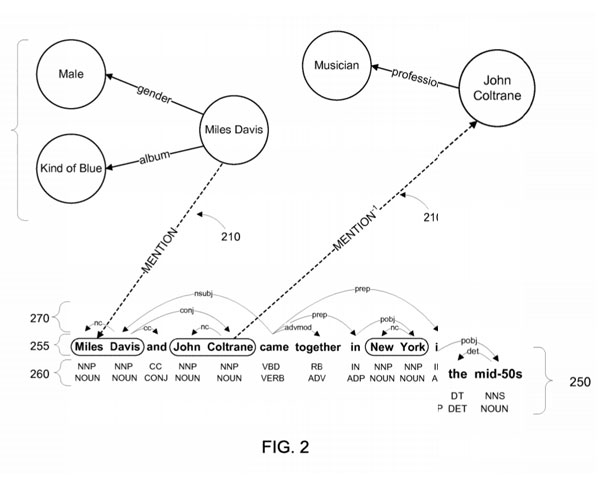
使用自然语言查询查询数据图
提交:2015年3月13日: 2020年10月20日
“实施方式包括用于查询数据图的系统和方法。一个示例方法包括接收培训的机器学习模块,以产生具有用于查询的多个特征的模型,每个特征表示数据图中的路径。该方法还包括接收包括第一搜索项的搜索查询,将搜索查询映射到查询,以及映射将第一个搜索项Ping到数据图中的第一个实体。该方法还可以包括使用第一实体和多个加权特征中的至少一个在数据图中识别第二实体,并在响应于搜索查询的响应中提供与第二实体有关的信息。一些实现还可以包括通过例如从答案生成正负训练示例的机器学习模块。“
戴夫的音符
这是有趣的,这是在2013年提交的。为什么?
因为它涉及语义元素,图形和实体。
很多SEO的职业赞助当时没有Clue那些东西就像很少谈论那样。
事实上,到这一天,很多SEO人们真的没有“得到”谷歌如何处理
语义
。
地狱,最近我仍然看到他们谈论古老方法作为
lsi。 说很多有机搜索行业都很好,并且在搜索这些日子如何实际工作时真正背后。
本专利的核心正在讨论如何过去很多实体关系和图形数据实际上是手动拼凑在一起的(你能想象吗?)并且他们正在寻求更自动化的机器学习。再次,这是2013年,我的朋友。
这不应该是过去几年的谈话点……但它已经存在。
无论如何,让我们看看一些兴趣点。
广告联交线读数下方
不能够在数据图中
“(…),诸如人,地方,事物,概念等的实体可以存储为节点,节点之间的边缘可以指示节点之间的关系。在这样的数据图中,节点“马里兰州”和“美国”可以被“在国家”和/或“有国家”的边缘联系。 “
”从文本和数据图中提取的知识用作培训机器学习算法的输入来预测数据图的元组。训练有素的机器学习算法可以为给定关系产生多个加权特征,每个特征表示两个实体如何相关的推断。 “
”一些实现允许从数据图中回答自然语言查询。在这样的实施中,可以培训机器学习模块以将功能映射到查询,并且用于提供可能的查询结果。训练可以涉及使用来自搜索记录的正示例或从基于文档的搜索引擎获得的查询结果。培训的机器学习模块可以产生多个加权特征,其中每个特征表示一个可能的查询答案,由数据图中的路径表示。 “
搜索和结构化信息卡
 提起检索:10月26日,2020Awarded :2020年11月3日
提起检索:10月26日,2020Awarded :2020年11月3日
“
”
“
”
“”“
”
“
”
“
”“”方法,系统,设备,包括在计算机存储介质上编码的计算机程序,便于识别额外的触发术语结构化信息卡。在一个方面,该方法包括访问与模板相关联的数据的动作,用于呈现结构化信息,其中访问的数据引用(i)标签术语和(ii)值。其他动作可以包括获得候选标签项,识别与标签项相关联的一个或多个实体,标识与候选标签术语相关联的一个或多个实体,以及用于一个或多个实体的每个特定实体与候选标签术语相关联,将与候选标签术语相关联(i)与特定实体相关联的标签项,(ii)与标签项相关联的值。“
戴夫的笔记
没有真正的地球 – 欺骗在这里,但确实向我们发出了信息卡,实体,知识库和结构化数据的感觉可以一起玩。
对于我来说,广告联系读数下面
,这是SEO多年来如何改变的另一个例子并且远远超过了似乎与生物的从业者和出版商在比斯的出版商相遇。
显着
“(…)卡触发 – 提供术语识别单元,其可以识别用于结构化信息卡的额外触发术语。卡触发术语识别单元允许通过评估结构化信息卡的语法中的潜在包含的候选术语来调整一个或多个结构化信息卡的语法。“
” ,假设一个“电影”的语法结构卡包括“电影时间”的术语“电影时间”,“电影票证确认”和“票证确认号码”。卡触发术语识别单元可以分析与“电影”结构信息卡和一个或候选查询的语法相关联的术语,并识别诸如触发期的“电影”结构化信息卡的额外触发期“电影票。”因此,接收的后续查询包括诸如“电影时间”,“电影票”,或两者之类的术语将响应于这些查询触发“电影”结构化信息卡的显示。“
广告Continue阅读下面这是关于本周的人。 一如既往地,永远不要忘记搜索引擎如何工作的和CO不断与您的学习和策略推动界限。下周见!
更多资源: 3最新的谷歌的兴趣专利 – 10月13日,2020 从2020年的前半部分
知识图中的个性化实体储存库
图像积分 特色图片:由作者创建的,11月20日期间在帖子中:USPTO
