在这些困难时期,以更少的时间和更少的资源完成更有效的工作比以往任何时候都更加重要。
一个经常被忽略的无聊且耗时的SEO任务是大规模编写引人注目的标题和元描述。
特别是当站点有数千或数百万个页面时。
当您不知道奖励是否值得时,很难付出努力。
在本专栏中,您将学习如何使用自然语言理解和生成的最新进展来自动生成高质量的标题和元描述。
我们将从Google表格中方便地访问这一令人兴奋的生成功能。 我们将学习以最少的Python和JavaScript代码实现该功能。
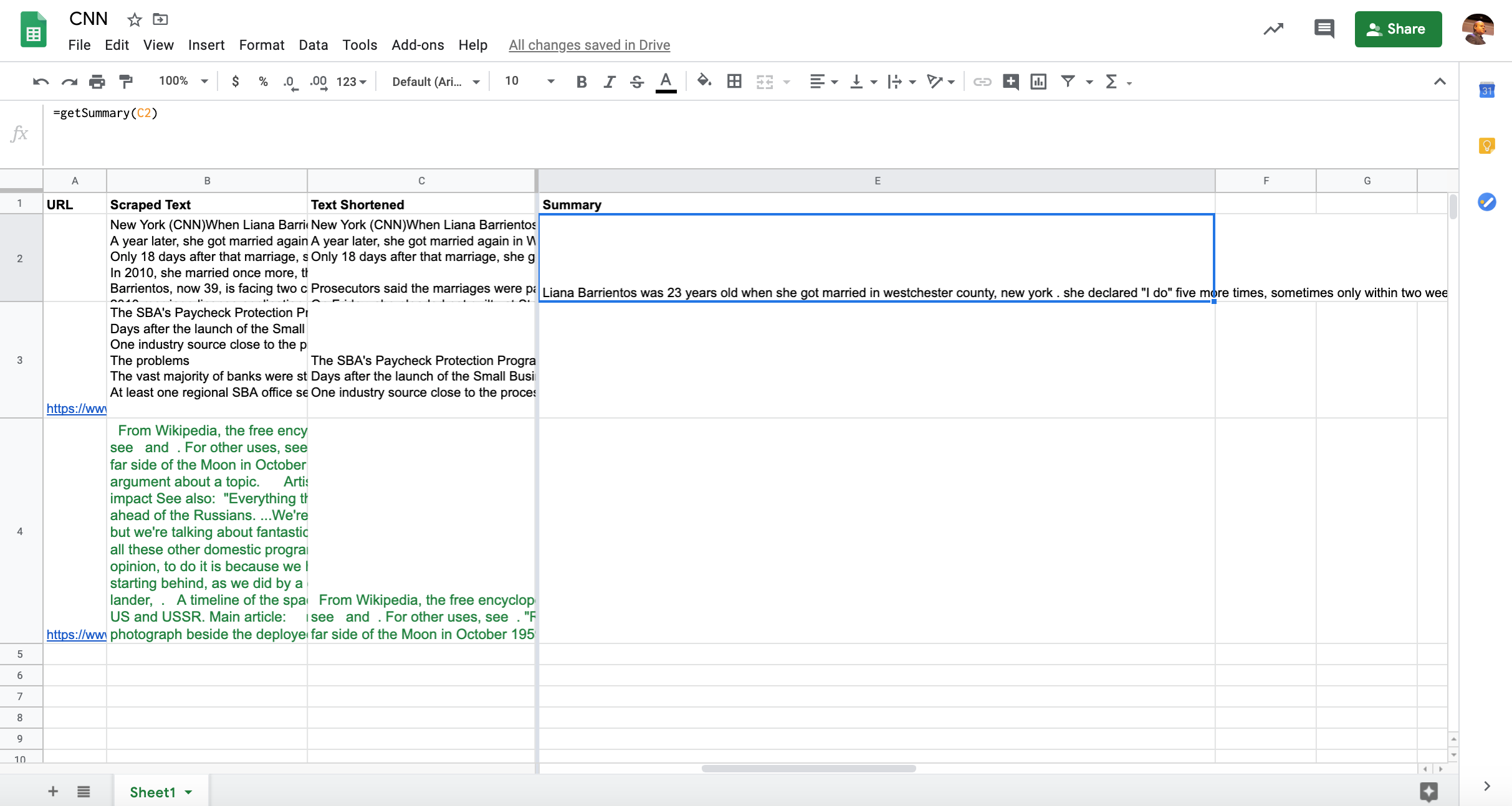
这是我们的技术计划:
- 我们将在Google Colab中实施和评估几个最新的文本汇总模型
- 我们将提供Google Cloud Function中的一种模型,可以从Apps Script和Google Sheets轻松调用这些模型
- 我们将直接从Google表格中抓取页面内容,并使用我们的自定义功能对其进行汇总
- 我们将使用RankSense将生成的标题和元描述部署为Cloudflare中的实验
- 我们将创建另一个Google Cloud Function来触发Bing中的自动索引
介绍拥抱面部变压器
Hugging Face Transformers是AI研究人员和从业者中流行的图书馆。
它为最新的自然语言研究提供了统一且易于使用的界面。
研究是使用Tensorflow (Google的深度学习框架)还是Pytorch (Facebook的框架)进行编码都没有关系。 两者都是最广泛采用的。
尽管转换器库提供了更简单的代码,但对于最终用户而言,它还不如Ludwig那么简单(我在先前的深度学习文章中已经介绍过Ludwig)。
随着变压器管道的引入,这种情况最近发生了变化 。
管道使用最少的代码封装了许多常见的自然语言处理用例。
它们还为基础模型的使用提供了很大的灵活性。
我们将使用转换器管道评估几种最新的文本汇总选项。
我们将从本笔记本中的示例中借用一些代码。
Facebook的BART
在宣布BART时,Facebook研究员Mike Lewis分享了他们论文中一些非常令人印象深刻的抽象总结。
我发现摘要性能出奇地好– BART确实能够将整个文档中的信息与背景知识相结合,以生成高度抽象的摘要。 以下是一些典型示例: pic.twitter.com/EENDPgTqrl
-Mike Lewis(@ml_perception) 2019年10月31日
现在,让我们看看使用变压器管道重现其工作结果有多么容易。
首先,让我们在新的Google Colab笔记本中安装该库。
确保选择GPU运行时。
!pip install transformers 接下来,让我们为其添加管道代码。
from transformers import pipeline # use bart in pytorch bart_summarizer = pipeline("summarization")
这是我们将总结的示例文本。
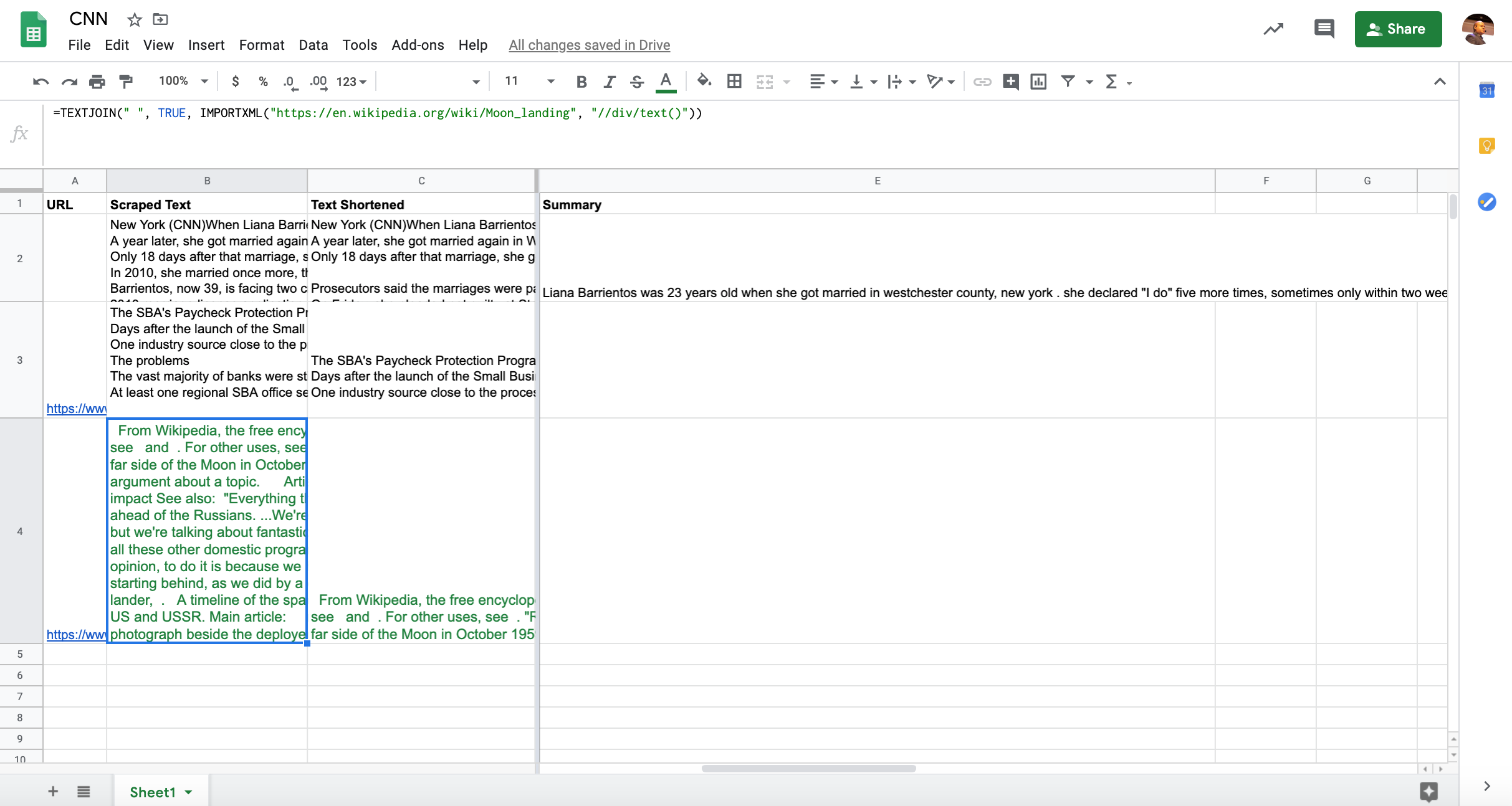
TEXT_TO_SUMMARIZE = """ New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York. A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband. Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared "I do" five more times, sometimes only within two weeks of each other. In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her "first and only" marriage. Barrientos, now 39, is facing two criminal counts of "offering a false instrument for filing in the first degree," referring to her false statements on the 2010 marriage license application, according to court documents. Prosecutors said the marriages were part of an immigration scam. On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further. After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002. All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say. Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages. Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted. The case was referred to the Bronx District Attorney\'s Office by Immigration and Customs Enforcement and the Department of Homeland Security\'s Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt, Turkey, Georgia, Pakistan and Mali. Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force. If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18. """
这是摘要代码和结果摘要:
summary = bart_summarizer(TEXT_TO_SUMMARIZE, min_length=50, max_length=250)
print(summary) #Output: [{'summary_text': 'Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the marriages were part of an immigration scam. She is believed to still be married to four men, and at one time, she was married to eight at once.'}]
我指定了生成的摘要不应少于50个字符,最多不超过250个字符。
这对于控制生成类型非常有用:标题或元描述。
现在,看看生成的摘要的质量,我们只键入了几行Python代码。
超酷!
'Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the marriages were part of an immigration scam. She is believed to still be married to four men, and at one time, she was married to eight at once.' print(len(summary[0]["summary_text"])) #Output: 249
谷歌的T5
最新的模型是文本到文本传输变压器,即T5。
该模型的一项令人印象深刻的成就是,其性能确实接近SuperGLUE排行榜中的人员水平基线。
Google的T5(文本到文本传输转换器)语言模型创造了新记录,并且在SuperGLUE基准测试中与人类非常接近。 https://t.co/kBOqWxFmEK
论文: https : //t.co/mI6BqAgj0e
代码: https: //t.co/01qZWrxbqS pic.twitter.com/8SRJmoiaw6—董(@yoquankara) 2019年10月25日
这是值得注意的,因为它在SuperGLUE中的NLP任务被设计为对人类来说很容易但是对机器来说却很难。
谷歌最近发布了一个摘要文章,其中包含了该模型的所有详细信息,以便人们不太愿意从研究论文中了解它。
他们的核心思想是在新的大规模培训数据集上尝试每个流行的NLP思想,这些数据集称为C4( 巨大的干净爬行语料库 )。
我知道,人工智能研究人员喜欢为自己的发明命名带来乐趣。
让我们使用另一个转换器管道来总结相同的文本,但是这次使用T5作为基础模型。
t5_summarizer = pipeline("summarization", model="t5-base", tokenizer="t5-base") summary = t5_summarizer(TEXT_TO_SUMMARIZE, min_length=50, max_length=250)
这是摘要文本。
[{'summary_text': 'in total, barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002 . she is believed to still be married to four men, and at one time, she was married to eight men at once .'}]
此摘要质量也很高。
但是我决定尝试更大的T5模型,该模型也可以作为管道使用,以查看质量是否可以提高。
t5_summarizer_larger = pipeline("summarization", model="t5-large", tokenizer="t5-large")
我一点也不失望。
真是令人印象深刻的总结!
[{'summary_text': 'Liana barrientos has been married 10 times . nine of her marriages occurred between 1999 and 2002 . she is believed to still be married to four men, and at one time, she was married to eight men at once .'}]
介绍云功能
现在,我们有了可以有效总结页面内容的代码,我们需要一种简单的方法将其公开为API。
在上一篇文章中 ,我使用Ludwig服务来做到这一点,但是由于我们此处未使用Ludwig,因此我们将采用另一种方法: Cloud Functions 。
云功能和等效的“ 无服务器 ”技术可以说是获取服务器端代码供生产使用的最简单方法。
它们被称为无服务器,因为您无需在托管提供程序中配置Web服务器或虚拟机。
我们将看到,它们极大地简化了部署体验。
部署Hello World Cloud功能
我们无需离开Google Colab即可部署我们的第一个测试Cloud Function。
首先,登录到您的Google Compute帐户。
!gcloud auth login --no-launch-browser
然后,设置一个默认项目。
!gcloud config set project project-name
接下来,我们将测试函数写入名为main.py的文件中
%%writefile main.py def hello_get(request): """HTTP Cloud Function. Args: request (flask.Request): The request object. Returns: The response text, or any set of values that can be turned into a Response object using `make_response` . """ return 'Hello World!'
我们可以使用此命令部署此功能。
!gcloud functions deploy hello_get --runtime python37 --trigger-http --allow-unauthenticated
几分钟后,我们将获得新API服务的详细信息。
availableMemoryMb: 256 entryPoint: hello_get httpsTrigger: url: https://xxx.cloudfunctions.net/hello_get ingressSettings: ALLOW_ALL labels: deployment-tool: cli-gcloud name: projects/xxx/locations/us-central1/functions/hello_get runtime: python37 serviceAccountEmail: xxxx sourceUploadUrl: xxxx status: ACTIVE timeout: 60s updateTime: '2020-04-06T16:33:03.951Z' versionId: '8'
而已!
我们不需要设置虚拟机,Web服务器软件等。
我们可以通过打开提供的URL和获取文本“ Hello World!”来对其进行测试。 作为浏览器中的响应。
部署我们的文本摘要云功能
从理论上讲,我们应该能够将文本摘要管道包装到一个函数中,并遵循相同的步骤来部署API服务。
但是,我必须克服一些挑战才能使它起作用。
首先,我们面临的第一个也是最具挑战性的问题是安装变压器库。
幸运的是,安装第三方软件包以在基于Python的Cloud Functions中使用很简单。
您只需要创建一个标准的requirements.txt文件,如下所示:
%%writefile requirements.txt transformers==2.0.7
不幸的是,这失败了,因为变压器需要使用Pytorch或Tensorflow。 它们都默认安装在Google Colab中,但需要为Cloud Functions环境指定。
默认情况下,Transformers使用Pytorch,当我按要求添加它时,它引发了一个错误,导致我进入了这个有用的Stack Overflow线程 。
我知道它可以与此更新的require.txt文件一起使用。
%%writefile requirements.txt https://download.pytorch.org/whl/cpu/torch-1.0.1.post2-cp37-cp37m-linux_x86_64.whl transformers==2.0.7
下一个挑战是模型的巨大内存需求和云功能的局限性。
我首先使用诸如NER这样的更简单的管道来测试功能,NER代表名称实体识别 。
我首先在Colab笔记本中对其进行测试。
from transformers import pipeline nlp_token_class = None def ner_get(request): global nlp_token_class #run once if nlp_token_class is None: nlp_token_class = pipeline('ner') result = nlp_token_class('Hugging Face is a French company based in New-York.') return result
我得到了这个故障响应。
[{'entity': 'I-ORG', 'score': 0.9970937967300415, 'word': 'Hu'}, {'entity': 'I-ORG', 'score': 0.9345749020576477, 'word': '##gging'}, {'entity': 'I-ORG', 'score': 0.9787060022354126, 'word': 'Face'}, {'entity': 'I-MISC', 'score': 0.9981995820999146, 'word': 'French'}, {'entity': 'I-LOC', 'score': 0.9983047246932983, 'word': 'New'}, {'entity': 'I-LOC', 'score': 0.8913459181785583, 'word': '-'}, {'entity': 'I-LOC', 'score': 0.9979523420333862, 'word': 'York'}]
然后,我只需添加%% writefile main.py即可创建可用于部署该功能的Python文件。
当我查看日志以了解API调用失败的原因时,我发现内存需求是一个大问题。
但是,幸运的是,您可以使用此命令轻松覆盖默认的250M限制和执行超时。
!gcloud函数部署ner_get- 内存2GiB-超时540-运行时python37 --trigger-http --allow-unauthenticated
我基本上指定了2GB的最大内存和9分钟的执行超时,以允许模型的初始下载(可以传输的千兆字节)。
我用来加速对同一Cloud Function的后续调用的一个技巧是使用全局变量将下载的模型缓存在内存中,并在重新创建管道之前检查它是否存在。
经过测试BART和T5功能并确定了一个T5小型模型,该模型非常适合Cloud Functions的内存和超时要求。
这是该功能的代码。
%%writefile main.py from transformers import pipeline nlp_t5 = None def t5_get(request): global nlp_t5 #run once if nlp_t5 is None: nlp_t5 = pipeline('summarization', model="t5-small", tokenizer="t5-small") TEXT_TO_SUMMARIZE = """ New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York... """ result = nlp_t5(TEXT_TO_SUMMARIZE) return result[0]["summary_text"]
这是部署它的代码。
!gcloud functions deploy t5_get --memory 2GiB --timeout 540 --runtime python37 --trigger-http --allow-unauthenticated
该功能的一个问题是要总结的文本是硬编码的。
但是我们可以通过以下更改轻松解决此问题。
%%writefile main.py from transformers import pipeline nlp_t5 = None def t5_post(request): global nlp_t5 #run once if nlp_t5 is None: #small model to avoid memory issue nlp_t5 = pipeline('summarization', model="t5-small", tokenizer="t5-small") #Get text to summarize from POST request content_type = request.headers['content-type'] if content_type == 'application/x-www-form-urlencoded': text = request.form.get('text') result = nlp_t5(text) return result[0]["summary_text"] else: raise ValueError("Unknown content type: {}".format(content_type)) return "Failure"
我只需确保内容类型是url编码的表单 ,然后从表单数据中读取参数文本 。
我可以使用以下代码在Colab中轻松测试此功能。
import requests url = "https://xxx.cloudfunctions.net/hello_post" data = {"text": text[:100]} requests.post(url, data).text
由于一切都按预期进行,因此我可以在Google表格中进行操作。
从Google表格调用我们的文本汇总服务
我在上一专栏中介绍了Apps脚本,它确实为Google表格提供了强大的功能。
我能够对我创建的功能进行较小的更改,以使其可用于文本摘要。
function getSummary(text){ payload = `text=${text}`; payload = encodeURI(payload); console.log(payload); var url = "https://xxx.cloudfunctions.net/t5_post"; var options = { "method" : "POST", "contentType" : "application/x-www-form-urlencoded", "payload" : payload, 'muteHttpExceptions': true }; var response = UrlFetchApp.fetch(url, options); var result = response.getContentText(); console.log(result); return result; }
就这样。
我更改了输入变量名称和API URL。
其余与我需要提交带有表单数据的POST请求相同。
我们运行测试,并检查控制台日志以确保一切正常。
是的
Apps脚本的一大限制是自定义功能的运行时间不能超过30秒 。
实际上,这意味着我可以总结文本(如果字符少于1200个字符),而在Colab / Python中,我测试了具有10,000个字符以上的全文。
对于较长的文本,更好的替代方法是像我在本文中所做的那样,从Python代码更新Google表格。
从Google表格中抓取页面内容
以下是表格中完整工作代码的一些示例。
既然我们已经能够汇总文本内容,那么让我们看看如何直接从公共网页中提取文本内容。
Google表格为此功能提供了一个称为IMPORTXML的强大功能。
我们只需要提供URL和一个XPath选择器即可识别我们要提取的内容。
这是从Wikipedia页面提取内容的代码。
=IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing", "//div/text()")
我使用了通用选择器来捕获DIV中的所有文本。
随意使用适合您目标页面内容的不同选择器。
虽然我们能够获取页面内容,但它可以分为多行。 我们可以使用另一个函数TEXTJOIN修复该问题 。
=TEXTJOIN(" ", TRUE, IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing", "//div/text()"))
在Bing中快速索引我们的新元描述和标题
那么,我们如何知道这些新的搜索片段比手动编写的片段表现更好,还是根本没有元数据?
确保学习的一种方法是运行实时测试。
在这种情况下,快速索引我们的更改至关重要。
我已经介绍了如何通过自动执行URL Inspection工具在Google中执行此操作。
这种方法将我们限制在几百页。
更好的选择是使用很棒的Bing快速索引API,因为我们可以请求为多达10,000个URL进行索引!
多么酷啊?
由于我们主要对衡量点击率感兴趣,因此我们的假设是,如果我们在Bing中获得更高的点击率,那么Google和其他搜索引擎也可能会发生同样的情况。
值得考虑的一项服务是允许发布者获得在Bing中立即建立索引的URL,并实际上在几分钟之内就开始排名的服务。 这就像免费的钱,为什么有人不接受呢? @sejournal @bing @BingWMC https://t.co/a5HkIpbxHI
-罗杰·蒙蒂(@martinibuster) 2020年3月20日
我必须同意罗杰。 这是执行此操作的代码。
api_key = "xxx" # Get your own API key from this URL https://www.bing.com/webmaster/home/api import requests def submit_to_bing(request): global api_key api_url=f"https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey={api_key}" print(api_url) #Replace for your site url_list = [ "https://www.domain.com/page1.html", "https://www.domain.com/page2.html"] data = { "siteUrl": "http://www.domain.com", "urlList": url_list } r = requests.post(api_url, json=data) if r.status_code == 200: return r.json() else: return r.status_code
如果提交成功,您应该期待此响应。
{'d': None}
然后,我们可以通过将另一个Cloud Function添加到我们的main.py文件中并像以前一样使用deploy命令来创建它。
在Cloudflare中测试我们生成的代码片段
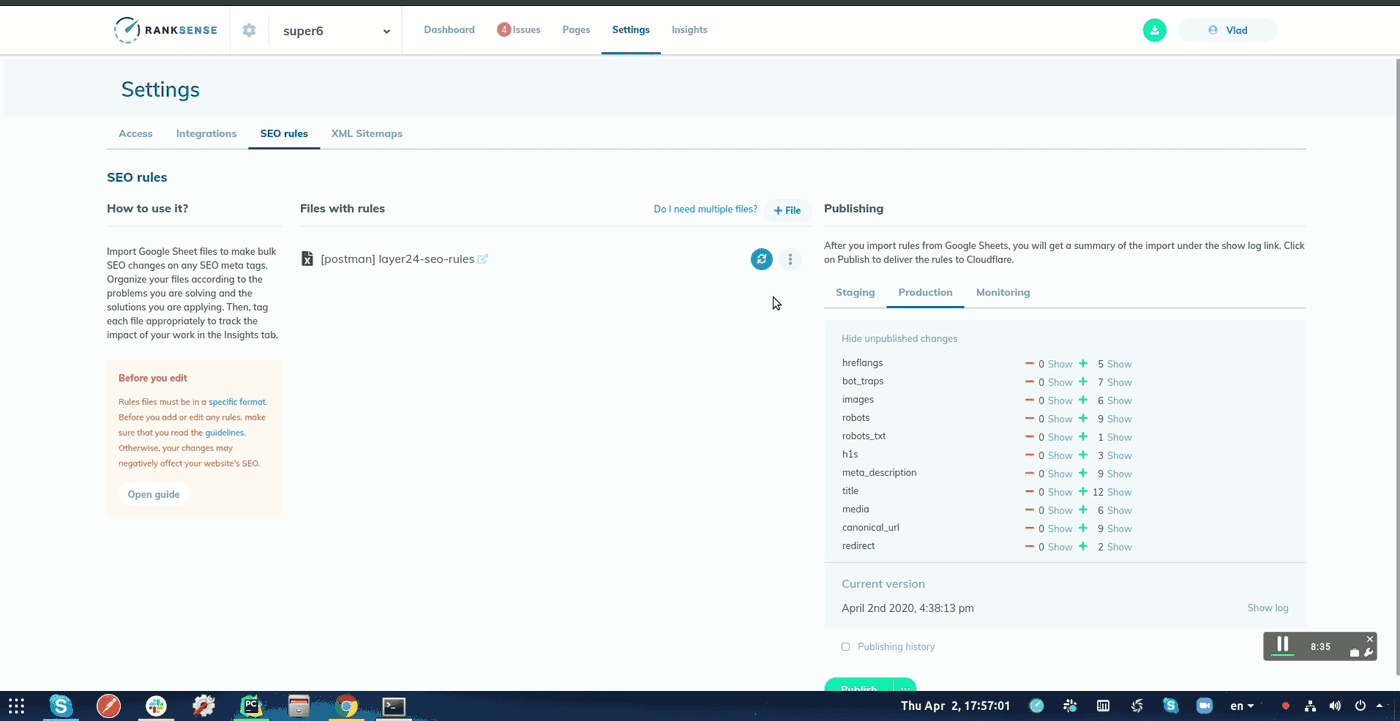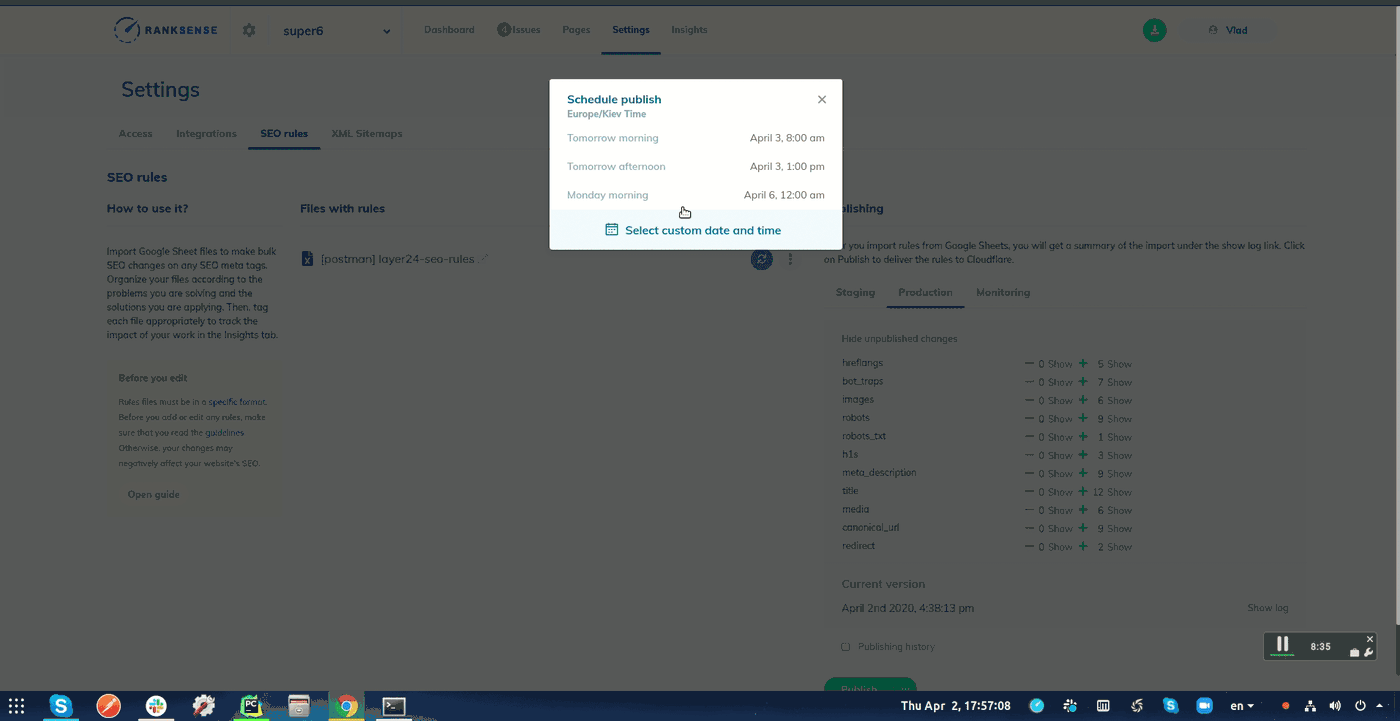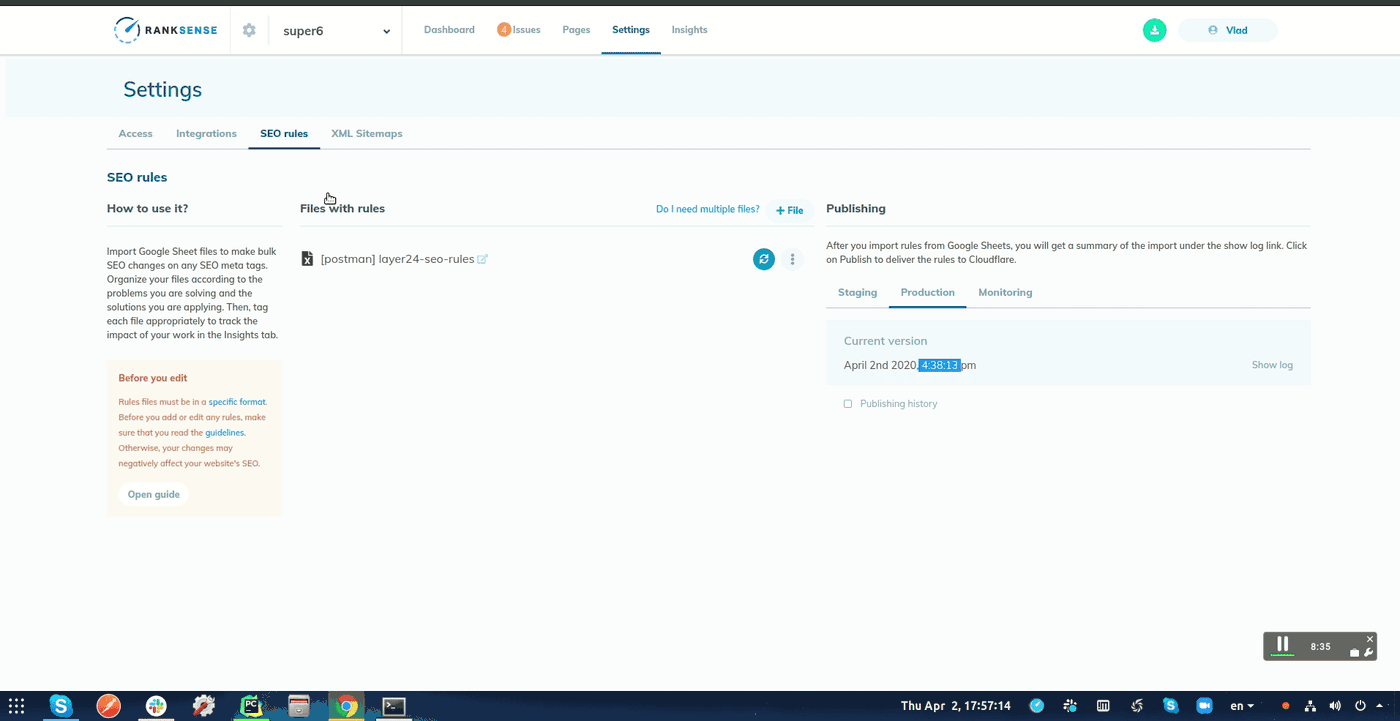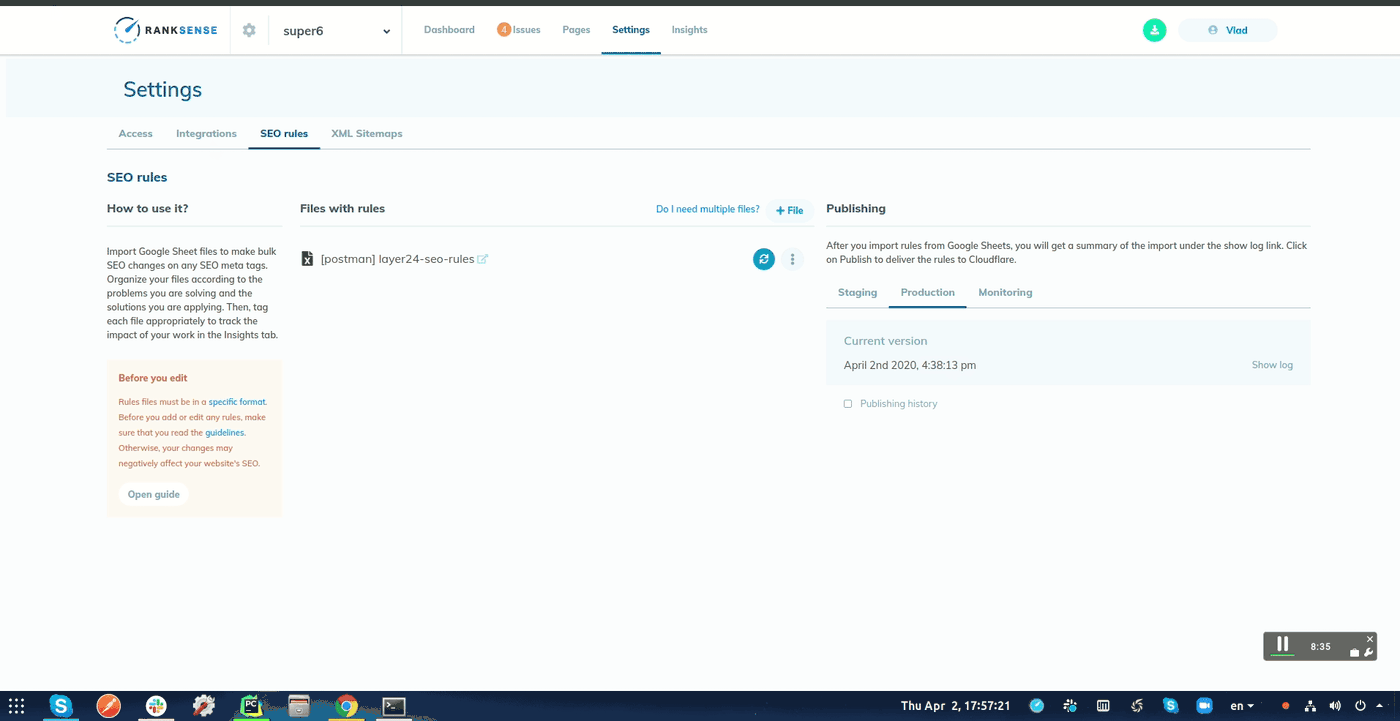
最后,如果您的网站使用Cloudflare CDN ,则可以在整个网站上进行部署之前,使用RankSense应用程序将这些更改作为实验运行。
只需将URL和文本摘要列复制到新的Google表格中,然后将其导入该工具即可。
发布实验时,您可以选择安排更改时间并指定Webhook URL。
Webhook URL允许应用程序和服务在自动化的工作流程中相互通信。
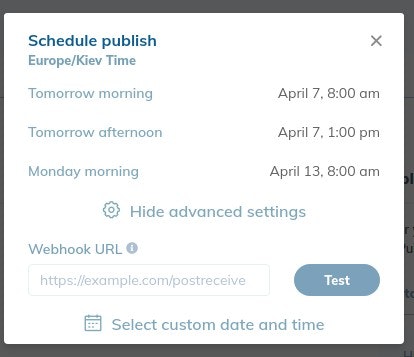
复制并粘贴Bing索引云功能的URL。 在Cloudflare中传播更改后15分钟,RankSense将自动调用它。
了解更多的资源
这里是一些链接的链接,这些链接在本文的研究过程中非常有用。
- 拥抱面部变形金刚教程
- 汇总管道
- Google Cloud Functions快速入门
- 使用Cloud Functions服务模型
- 必应提交API
- Bing提交API教程
- RankSense Webhook API
图片积分
作者的所有屏幕截图,2020年4月
