python库是一个有用的函数和代码的集合,允许您完成许多任务而无需从头开始编写代码。
有超过100,000个用于Python的库,可以用于从数据分析到创建视频游戏的功能。
在本文中,您可以找到我用于完成SEO的几个不同的库项目和任务。所有这些都是初级友好的,您可以找到充足的文档和资源来帮助您开始。
为什么是Python Librar对SEO有用的IES?每个Python库包含可用于执行不同任务的所有类型(阵列,词典,对象等)的函数和变量。
以下
的广告传票读数例如,SEO可以用来自动化某些事情,预测结果,并提供智能洞察力。
可以使用Vanilla Python,但是图书馆可以是
用来制作任务更轻松地
并更快地编写和完成。 SEO任务的Python库
有许多有用的Python库对于SEO任务,包括
数据分析
,Web刮擦,以及可视化洞察力。
这不是一个详尽的清单,但这些是我发现自己为SEO目的使用最多的库。 PANDAS
PANDAS是用于与表数据一起使用的PYTHON库。它允许高级数据操作,其中密钥数据结构是DataFrame。
数据标记类似于Excel
电子表格
,但是,它们不限于行和字节限制,也是如此更快,更高效。
使用熊猫的最佳方式是采取简单的数据的简单CSV(例如,您的网站的爬网),并将其作为DataFrame保存在Python中。
下面的广告传票读数
一旦您存储在Python中,您可以执行多个不同的分析任务,包括聚合,枢转和清洁数据。例如,如果我有完整的网站爬网并希望仅提取Indexab的那些页面LE,我将使用内置熊猫函数仅包括我的DataFrame中的网址。
将熊猫导入pd df = pd.read_csv(’/ users / rutheerett / documents / folder / file_name.csv’ )df.headindexable = df [(df.indexable == true)]索引
请求
下一个库称为请求,用于在Python中进行HTTP请求。
请求使用不同的请求方法,例如Get和Pock以提出请求,结果存储在Python中。
此操作的一个示例是一个简单的URL的请求,这将打印出来页面状态代码:
决策功能,200个状态代码意味着PAGE可用,但是404表示找不到页面。
如果response.status_code == 200:打印(’成功!’)elif response.status_code == 404:打印(“未找到”)
您还可以使用不同的请求,例如标题,其中显示有关内容类型的页面的有用信息,或者缓存响应需要多长时间。
标题= response.headersprint(标题)response.heading.headers [‘content-type’]
63]标题= {'用户 - 代理':'mozilla / 5.0(兼容; googlebot / 2.1; + http://www.google.com/bot.html)'} ua_response = requests.get('https ://www.deepcrawl.com/',标题=标题)打印(ua_respONSE)
美丽的汤
美丽的汤是从HTML和XML文件中用于提取数据的库。
有趣的事实:Beautifulsoup库实际上以Lewis Carroll梦游仙境的奇妙探险诗歌的诗歌命名。
作为一个库,referrysoup用于绘制Web文件的感觉并是最常用于Web擦除,因为它可以将HTML文档转换为不同的Python对象。
例如,您可以使用URL并将漂亮的汤与请求库一起使用,以提取页面的标题。
 来自bs4 import beautifueoup导入requestssurl =’https://www.deepcrawl.com’req = predings.get(url)汤= beautysoup(req.text,“html.parser”)标题=汤。山雀Le Print(标题)
来自bs4 import beautifueoup导入requestssurl =’https://www.deepcrawl.com’req = predings.get(url)汤= beautysoup(req.text,“html.parser”)标题=汤。山雀Le Print(标题)
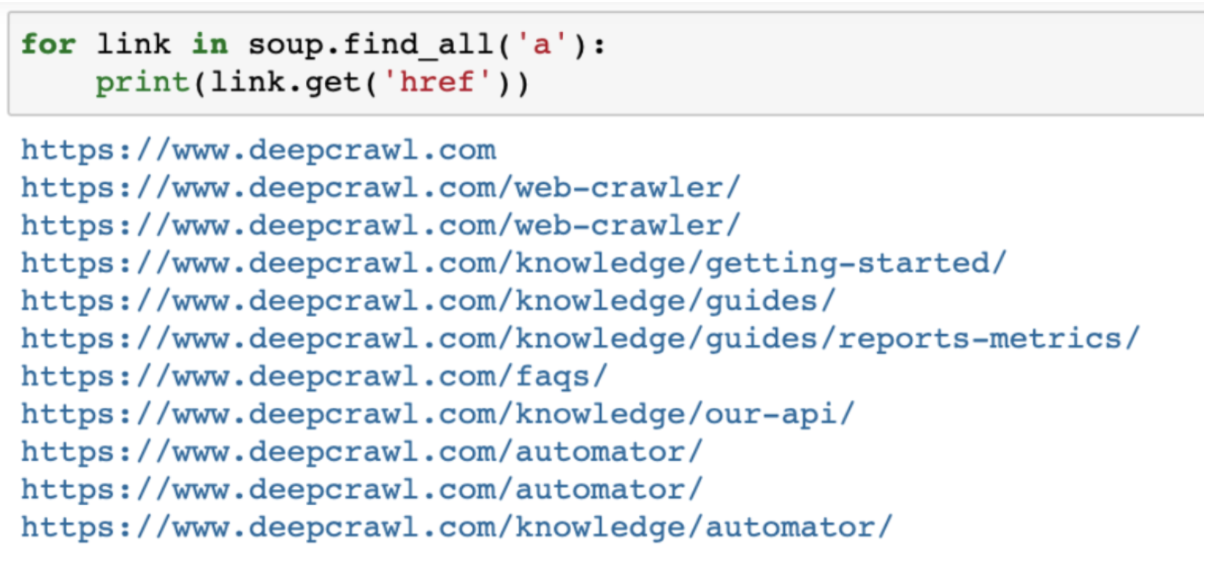
页面上的HREF链接:
rel下面 r =’https://www.deepcrawl.com/knowledge/technical-seo-library/’req = requests.get(url)汤= feedsoup( req.text,“html.parser”用于汤中的链接(’a’):print(link.get(’href’))
r =’https://www.deepcrawl.com/knowledge/technical-seo-library/’req = requests.get(url)汤= feedsoup( req.text,“html.parser”用于汤中的链接(’a’):print(link.get(’href’))
将它们放在一起
这三个库也可以一起使用,用于使HTTP请求对页面的请求一起使用,我们希望使用BeauteSoup从中提取信息。
然后,我们可以将该原始数据转换为Pandas DataFrame以执行进一步的分析。
URL =’HTTPS://www.deepcrawl.com/blog/’req = requests.get(url)汤= beautysoup(req.text,html.parser“)链接= soup.find_all(’a’)df = pd.dataframe({ “链接”:链接})DF
matplotlib和seaborn
matplotlib和seaburs是用于创建可视化的两个python库。
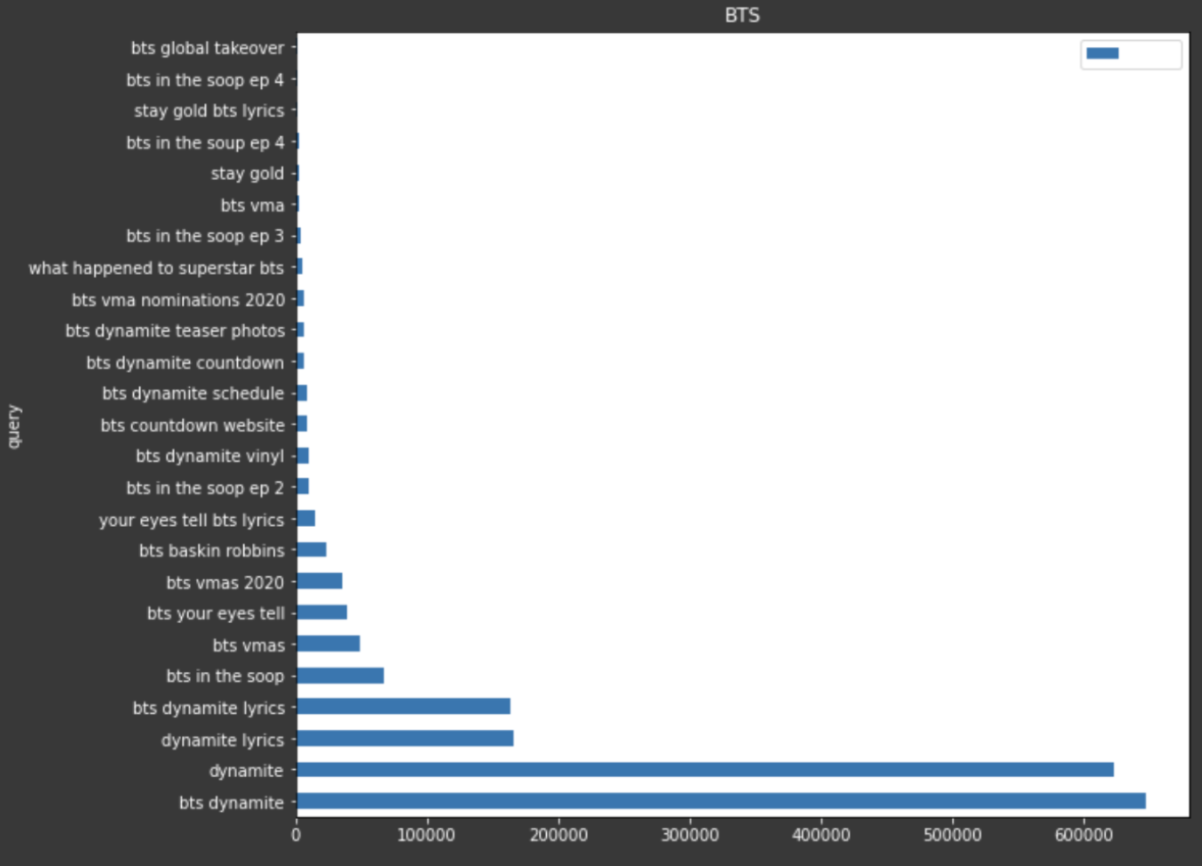
matplotlib允许您创建许多不同诸如条形图,行,直方图等的数据可视化,甚至是热插拔。
下面
的广告联系读数例如,如果我想采取一些谷歌趋势数据以在30的时间内显示最受欢迎的疑问天,我可以在matplotlib中创建一个条形图,以便可视化所有这些。
在Matplotlib上建立的海运提供了甚至更多可视化模式,如除了线条和条形图之外的散点图,盒子图和小提琴图。它与Matplotlib略有不同,因为它使用较少的语法并具有内置的默认主题。广告联网读数下面
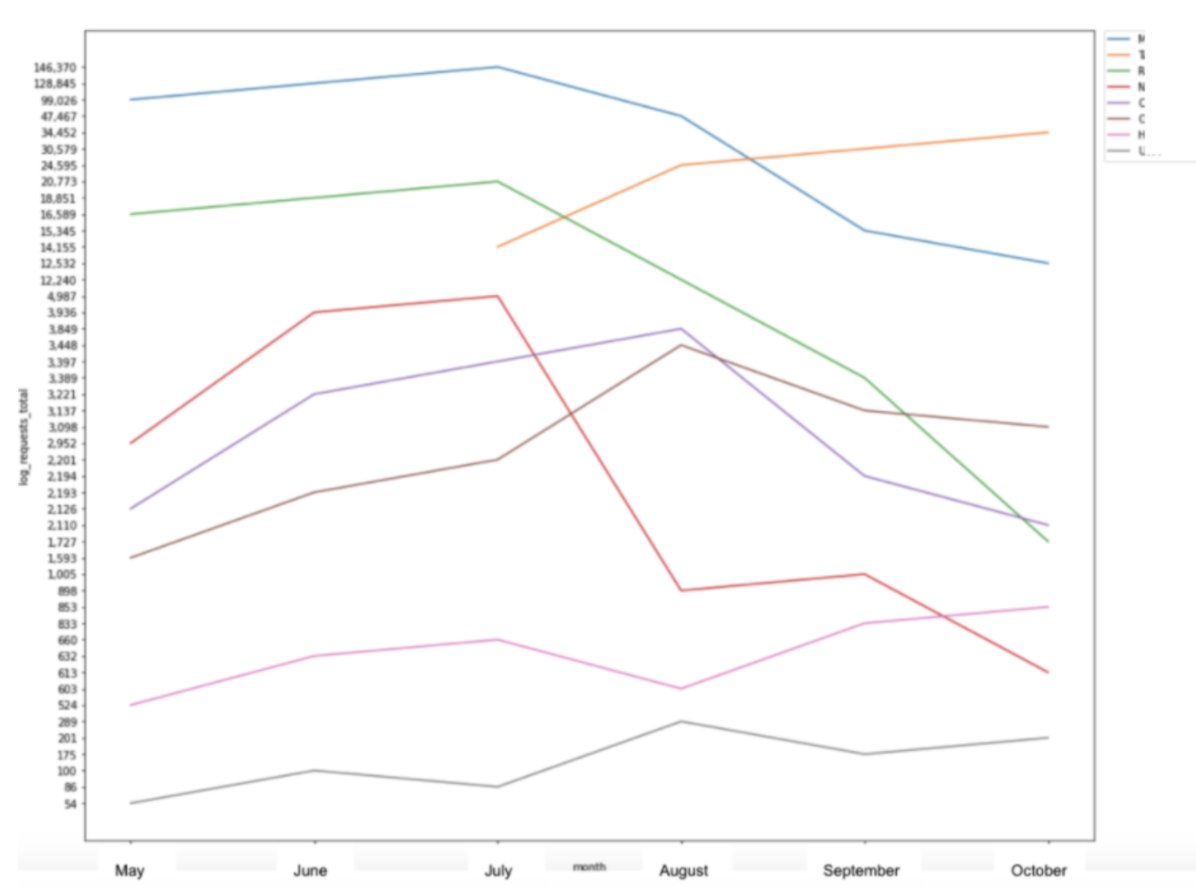
一个我用Seaborn的方法是,以可视化的日志文件命中一个网站,随着时间的某些细分创建线图。
SNS.LINEPLOT(x =“月”,y =“log_requests_total”,hue =’category’,data = pivot_status)plt.show() 此特定示例从枢轴表中获取数据,我能够使用Pandas库在Python中创建,并且是这些库一起工作的另一种方式,共同创建来自数据的易于理解的图片。
advertools
advertools
是由创建的库] elias dabbas 可用于帮助基于我们作为SEO专业人员和数字营销人员的数据来管理,理解和做出决策。
下面
网站地图分析 地点分析
图
该库允许您执行多个不同的任务,例如下载,解析和分析 XML站点地图以提取模式或分析内容的添加或改变的频率。
robots.txt分析
你可以用这个库做的另一个有趣的事情是将一个函数用作
提取一个网站的robots.txt
进入dataframe,按顺序轻松理解和分析规则集。
您还可以在库中运行测试,以检查特定用户代理是否能够获取CERTA在URL或文件夹路径中。
URL分析
roidools还使您能够解析和分析URL
以提取信息,更好地理解分析,serp和某些网址组的爬网数据。
您还可以使用库拆分URL来确定正在使用的HTTP方案,主路径,附加参数和查询字符串等内容。
硒硒是硒是一般用于自动化目的的Python文库。最常见的用例是测试Web应用程序。
下面的广告传票读数读取的硒读取的一个流行的例子是打开浏览器的脚本,并以定义的序列执行许多不同的步骤,例如填写表单或点击某些butons。
硒采用与我们之前所涉及的请求库中使用相同的原则。
但是,它不仅发送请求并等待响应,还可以呈现网页正在请求。要开始使用Selenium开始,您将需要一个Webdriver才能与浏览器进行交互。
每个浏览器都有自己的webdriver; Chrome有染色体和Firefox,例如Geckodriver。
这些很容易与您的Python代码下载和设置。以下是解释设定过程的有用文章,具有示例项目。
Scapy
Scrapy
我想在本文中涵盖的最终图书馆是Scape。
虽然我们可以使用请求模块来爬网和提取内部数据从网页来源,为了通过该数据和提取有用的洞察力,我们还需要将其与BreauteSoup结合起来。在下面的 Scrapy的广告联系读数基本上允许您在一个库中执行这两个。
Scrapy也更快,更强大,完成了请求爬网,提取和解析数据的序列,并允许您屏蔽数据。
在SCRAPY中,您可以定义多个指令(如)您想要抓取的域名,启动URL和某些页面文件夹的名称是允许或不允许爬网的。
rucate可用于提取某个页面上的所有链接例如,将它们存储在输出文件中。 class superspider(crawlspider):name =’提取器’允许_Domains = [‘www.deepcrawl.com’] start_urls = [‘https://www.deepcrawl.com/knowledge/technical-seo-library/’] base_url =’https://www.deepcrawl.com’def parse (self,response):对于response.xpath中的链接(’// div / p / a’):faility {“link”:self.base_url + link.xpath(’.// href’)。get() 您可以进一步迈出这一步,然后遵循网页上的链接,以从从起始URL链接到的所有页面中的信息,类似于Google查找的小规模复制在页面上的链接下。 /en.wikipedia.org/wiki/web_scraping’]base_url =’https://en.wikipedia.org’custom_settings = {‘depth_limit’:1} def解析(self,response):respond.xpath中的next_page(’// div / p / a’):产量response.follow(next_page,self.parse)在response.xpath(’// h1 / text()’):caility {‘quote’:quote.extract()}
了解更多信息这些项目在其他示例项目中,在这里
总是说,“学习的最佳方式是做。“
读数下面的广告联系读数
我希望发现一些可用的图书馆启发了您开始学习Python或加深知识。 Python来自SEO行业的Python贡献哈姆雷特也喜欢分享来自Python SEO社区中的eScly和项目。为了纪念他鼓励他人的热情,我想分享我从社区中看到的一些惊人的事情。 作为对哈姆雷特和SEO Python社区的致敬,他帮助培养了
Wargnier
创造了SEO Pythonistas,为SEO社区创造了惊人的Python项目的贡献。 哈姆雷特对SEO社区的无价贡献得到了特色。
moshe Ma-Yafit 创建了一个超级
日志文件分析的COOL脚本
,并且在此帖子中介绍了脚本的工作原理。它能够显示包括谷歌BOT的可视化,通过设备,每日命中按响应代码,响应代码%总数和更多。
KorayTuğberkGübür
目前正在制作地图卫生检查员。他还举办了一个RevalSense Webinar,elias dabbas在那里分享了一个脚本,记录SERPS和分析算法。
广告联系读数下面
它基本上记录了常规时间差异的SERP,并且您可以抓取所有登陆页面,混合数据并创建一些相关性。
John Mcalpin 写了一篇文章,详细说明了如何使用
Python和Data Studio在竞争对手上间谍的文章。 JC Chouinard 写了一个使用Reddit API
的完整指南。有了这个,您可以执行诸如从RedDIT和发布到子文件中的数据提取数据。
Rob可以正在研究新的GSC分析工具并建立几个新的D.Wix中的省略/真实部位在记录它的同时测量其高端WordPress竞争对手。 Masaki Okazawa
还共享一个脚本,分析使用Python的Google搜索控制台数据。
🎉 Happy #rstwittorial
星期四与 @saksters 🥳 用 #python &#128293 ; 这是输出👇二月RankSense(@RankSense) 25,2021 – pic.twitter.com/9l5Xc6UsmT 更多资源: 如何使用Python&JavaScript自动执行URL检测工具 6 SEO任务以Python自动化 高级技术SEO:a完整指南广告联网读数下方 图像信用 所有屏幕截图,3月2021日3月
