在日志文件中发现的搜索引擎爬网数据是任何SEO专业人员的奇妙信息源。
通过
分析日志文件
,您可以了解搜索引擎的准确性爬行和解释您的网站 – 清晰度您只需依赖第三方工具时无法获得。这将允许您通过提供搜索引擎如何表现的无可争议的证据来验证您的理论。提高您的通过帮助您了解解决问题的规模和修复它的可能影响的调查结果。在使用其他数据源时不可见的其他问题。但尽管存在众多好处,但不使用日志文件数据频繁的原样。原因是可以理解的:
访问DATA通常涉及通过DEV团队进行,这可能需要
时间
。原始文件可以是巨大的,并以不友好的格式提供,因此解析数据
努力
。设计制作在数据可以管道之前可能需要更容易地集成过程,并且成本可以禁止。在下面所有这些问题都是对进入的完全有效的障碍,但他们不受欢迎必须是不可克制的。 通过一些基本编码知识,您可以自动化整个过程。这正是我们在使用 Python
的逐步课程中要做什么来分析SEO的服务器日志。
你会找到一个脚本来让你开始,也是。初步考虑
最大的追疑之一解析日志文件数据中的ENGES是潜在格式的纯粹数量。 apache
,
nginx
,和
IIS IIS 提供一系列不同的选项,并允许用户自定义返回的数据点。 进一步复杂化问题,现在许多网站使用 CDN PloudFlare,CloudFront和Akamai等提供商,以从最接近的边缘位置向用户提供内容。这些都有自己的格式。
我们将专注于此帖子的组合日志格式,因为这是nginx的默认值以及Apache服务器的常见选择。
如果您不确定您正在处理的格式,因此,Buildwith和Wappalyzer等服务均提供有关网站的技术堆栈的优秀信息,请读取
如果您不确定,则提供有关网站的技术堆栈的优秀信息。 T.嘿,如果您没有直接访问技术利益相关者,嘿可以帮助您确定此功能。 仍然没有更聪明?尝试打开一个原始文件。
通常,在特定字段上提供了关于特定字段的信息,然后可以被交叉引用。
#fields:时间c-ip CS-Method CS-Uri-Stem SC-Status CS-Version
17:42:15 172.16.255.255获取/default.htm 200 http / 1.0
另一个考虑因素是我们想要包含的搜索引擎,因为这需要考虑我们的初始过滤和验证。
简化事物,我们将专注于谷歌,鉴于其主导
88%美国市场份额。
让我们开始。
1。识别文件和确定格式
要执行有意义的SEO分析,我们需要最少〜100k的请求和2-4周’的平均站点的价值。由于所涉及的文件大小,日志通常被分成单独的日子。它实际上保证您会收到多个文件来处理。
如我们不知道我们在运行脚本之前将它们组合的文件,否则我们将如何处理它们,这是一个重要的第一步是生成使用
Glob
模块的文件夹中所有文件的列表。
这允许我们返回与我们指定的模式匹配的任何文件。作为示例,以下代码会匹配任何TXT文件。
导入globfiles = glob.glob(’*。txt’)
日志文件可以以各种文件格式提供,但是,不仅仅是txt。
实际上,有时文件扩展名可能不是你识别的文件Ize。这是来自Akamai的日志递送服务的原始日志文件,它完美地说明了这一点: Bot_log_100011.ESW3C_WAF_S.20216025000000-2000-41
另外,收到的文件可能会跨多个子文件夹拆分,我们不想浪费时间将这些复制到一个奇异的位置。
庆幸地,Glob支持递归搜索和通配符运营商。这意味着我们可以生成子文件夹或子文件子文件夹中的所有文件的列表。
读数下面
文件= glob.glob(’** / *。*’,recursive = true)
接下来,我们希望识别我们列表中的文件中的文件类型。为此,可以检测到特定文件的
mime类型
。这将告诉我们我们正在处理的档案究竟是什么类型的文件无论扩展如何,都可以使用Python-Magic,围绕libmagic c库的包装器来实现,并创建一个简单的功能。
pip安装python-magicpip安装libmagic
导入magicDef file_type(file_path):mime = magic.from_file(file_path,mime = true)return mime
列表理解
然后可以使用我们的文件来循环应用函数,创建字典来存储名称和类型。
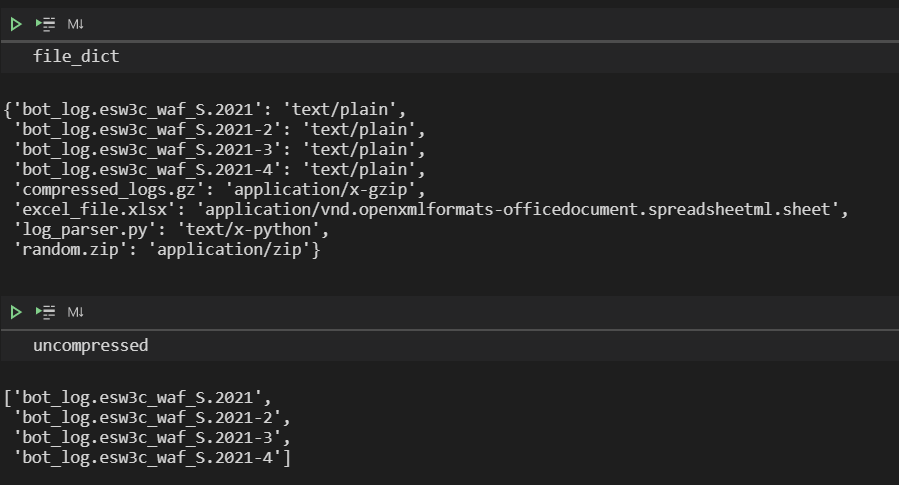
file_types = [file_type(文件)文件中文件中的文件] file_dict = dict(zip(文件,file_types))
最后,循环的函数和,以提取返回MIME类型的文本/简单的文件列表,并排除其他任何内容。
未压缩= [] def file_identifier(文件):对于关键,价值在file_dict.items()中:如果文件中的文件:dilon_identifier(’text / plain’):file_dict中的文件(’text / plain’)
2。提取搜索引擎请求
在筛选文件夹中的文件后,下一步是通过仅提取我们关心的请求来筛选文件本身。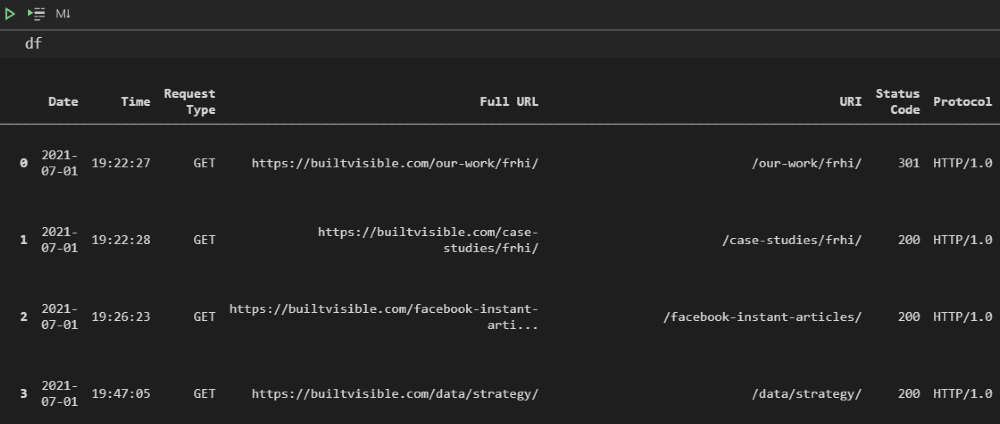 广告联系读数以下
广告联系读数以下
这删除了将文件组合使用命令行实用程序(如 grep 或 Findstr
),通过打开笔记本选项卡和书签保存不可避免的5-10分钟搜索以查找正确的命令。
在这种情况下,因为我们只想要Googlebot请求,搜索“GoogleBot”将匹配所有
相关用户代理s
我们可以使用Python的开放函数来读写我们的文件和Python的Regex模块Re,执行搜索。
导入Repattern =’GoogleBot’new_file =打开(’./googlebot.txt’,’w’,encoding =’utf8’)对于未压缩的txt_files:with open(txt_files,’r’,encoding =’utf8’)作为text_file:在text_file中为行:如果重新。搜索(图案,行):new_file.wriote(行)
Regex使得这种易于使用或运算符进行缩放。
模式='googlebot | bingbot'
3。解析请求
在
上次帖子
中,哈姆雷特Batista提供了有关如何使用Regex解析请求的指导。 作为一种替代方法,我们将使用
作为一种替代方法,我们将使用
Pandas ”强大的内置CSV解析器和一些基本数据处理功能功能ovs to:删除不必要的列.Format the timeStamp.Create具有完整URL.RENAME的列并重新排序剩余列。而不是硬编码域名,可以使用
输入
功能提示用户并将其另存为变量。
redult_url =输入(’使用协议输入完整域名:’)#获取来自用户inputdf = pd.read_csv(’./ googlebot。 ,sep =’\ s +’,error_bad_lines = false,header = none,low_memory = false)#导入logsdf.drop([1,2,4],轴= 1,inplace = true)#删除不需要的列/ chibledf [3] = df [3] .tr.replace('[‘,”)#分割时间戳到twodf[[‘日期’,’time’]] = df [3] .str.split(’:’ ,1,展开= true)df[[‘请求类型’,’URI’,’Protocol’]] = DF [5] .str.split(”,2,展开= true)#拆分URI REQ对columnsdf.drop([3,5],轴= 1,inplace = true)df.rename(列= {0:’IP’,6:’状态代码’,7:’字节’,8:’推荐人URL’,9:’用户代理’},inplace = true)#rename columnsdf [‘full url’] = tall_url + df [‘uri’]#concatenate域namedf [‘date’] = pd.to_datetime(df [‘日期’])#声明数据类型DF[[状态代码’,’字节’]] = df[[‘状态代码’,’字节’]]。应用(pd.to_numeric)df = df[[‘日期’, ‘time’,’请求类型’,’完整URL’,’URI’,’状态代码’,’协议’,’引用者URL’,’bytes’,’用户代理’,’ip’] #reorder列
4。验证请求
它非常易于欺骗搜索引擎用户代理,使请求验证成为过程的重要部分,以免通过分析我们自己的第三方爬行来实现虚假的结论。
[12要执行此操作,我们将安装一个名为
dnspython 的库,并执行反向DNS。 Pandas可用于删除重复的IPS并在此较小的DataFrame上运行查找,在重新应用结果并过滤掉任何无效请求之前。
从DNS导入解析器中读取以下
,ReverseNamedeF Reversedns(IP):TRY:Return str(ReverseName.from_address(IP),’Ptr ‘)[0])除外:返回’n / a’logs_filtered = df.drop_duplicates([‘ip’])。复制()#创建DF与checklogs_filtered [‘dns’] = logs_filtered [‘ip’的Dupliate IPS。 ] .Apply(reversedns)#使用反向IP DNS RESEURSLOGS_FILtered = DF.Merge(logs_filtered[[‘ip’,’dns’]],=’left’,ON = [‘ip’])#merge DNS列到完整日志s匹配iplogs_filtered = logs_filtered [logs_filtered [‘dns’]。str.Contains(’googlebot.com’)]#过滤器验证googlebotlogs_filtered.drop([‘ip’,’dns’],轴= 1,inplace = true) #丢弃DNS / IP列
采取这种方法将大大加快查找,在几分钟内验证数百万个请求。
在下面的例子中,26岁的情况下处理了〜400万行请求几秒钟。
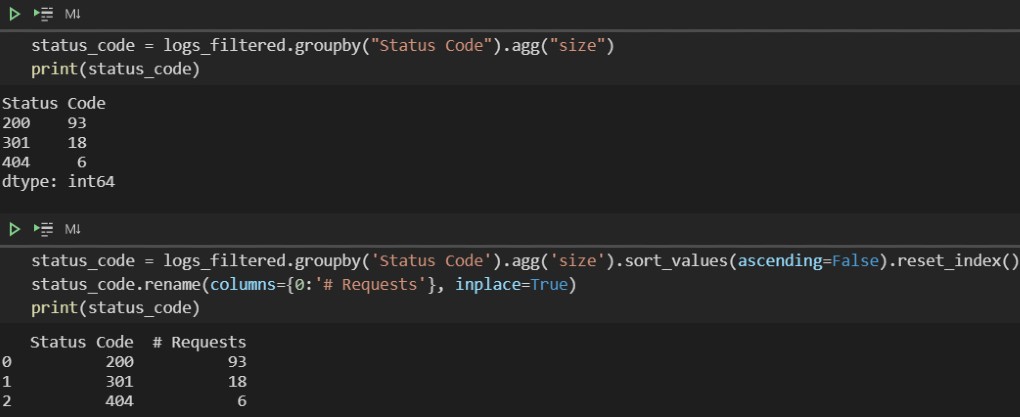
验证后数据
验证后,我们留下了一种清洁的,格式化的数据集,可以开始将该数据转移以更容易地分析数据点。 首先,让我们使用Pandas
GroupBy
和
AGG 函数以庞大的汇集从一些简单的聚合开始,以执行不同s的请求数的计数tatus代码。 distration_code = logs_filtered.groupby(’status code’)。AGG(’size’)
复制您在Excel中的数量,它是值得注意的是,我们需要指定’size’的聚合函数,而不是’count’。
使用count将在DataFrame内的列中的函数调用函数,并处理null值不同。重置索引将恢复两个列的标题,后者列可以重命名为更有意义的东西。
status_code = logs_filtered.groupby(’状态代码’)。agg (’size’)。sort_values(ascending = false).reset_index()status_code.rename(列= {0:’#请求’},inplace = true)
对于更高级数据操纵,Pandas’内置 PIVOT表
提供与Excel相当的功能,使复杂聚合成为可能的奇异代码。
在其最基本的级别处,该函数需要指定的DataFrame和索引 – 如果需要多索引,并且返回相应的值,并且返回相应的值。
PD.Pivot_table(logs_filtered,索引[‘完整URL’)
更大的特异性,可以声明所需的值和聚合 – 总和,平均值等 – 使用AGGFunc参数应用。
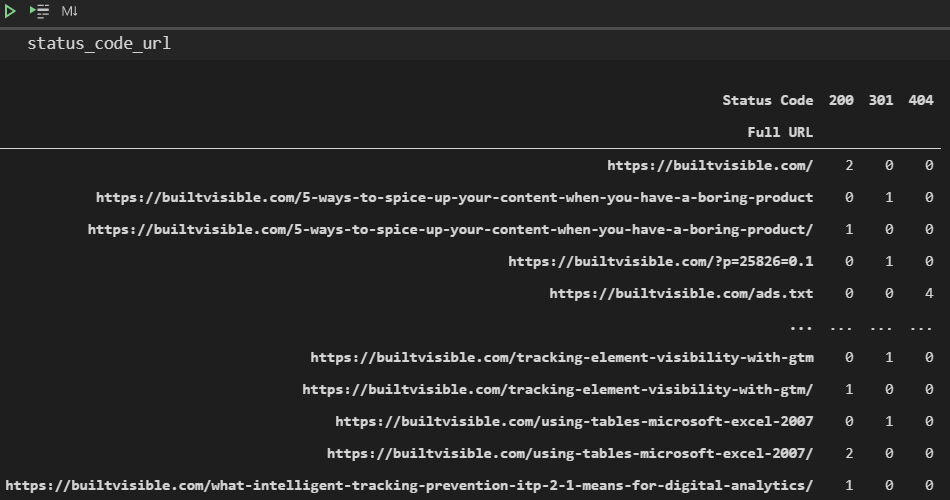
也值得一提,列对于列参数,它允许我们水平显示更清晰的输出的值。 status_code_url = pd.pivot_table(logs_filtered,index = [‘full url’],columns = [‘status代码’],aggfunc =’size’,fill_value = 0)[图
这里是一个稍微复杂的例子,它提供了每天每个用户代理人爬行的唯一URL的计数,而不是仅仅是请求数量的计数。
user_agent_url = pd.pivot_table(logs_filtered,index = [‘用户代理’],值= [‘full url’],columns = [‘date’],aggfunc = pd.series.nunique ,fill_value = 0)
如果您仍然努力与语法挣扎,请退出 mito 。它允许您在使用jupyterlab时与jupyter内的可视界面进行交互,但仍会输出相关代码。在下面的
结合范围
读取的数据点这可能有许多不同的数值,桶数据有意义。
要这样做,我们可以定义o列表中的间隔,然后使用
剪切
函数将值对箱子进行排序,指定np.inf以捕获最大值的最大值以上。
byte_range = [0,50000, 100000,200000,500000,1000000,np.inf] bytes_grouped_ranges =(logs_filtered.groupby(pd.cut(logs_filtered [‘bytes’],bins = byte_range,precision = 0)).agg(’size’).reset_index() )bytes_grouped_ranges.rename(列= {0:’#请求’},inplace = true)
在输出中使用间隔符号来定义精确范围,例如
(50000 100000]
圆括号指示当数字是<= 1048576: logs_filtered.to_excel(writer, sheet_name='Master', index=False)else: logs_filtered.to_csv('./logs_export.csv', index=False)
而不是
,并且当包括时的方括号。因此,在上面的示例中,桶包含值为50,001和100,000之间的数据点。
6。出口
我们进程中的最后一步是导出日志数据和枢轴。
为了易于分析,将其导出到Excel文件(XLSX)而不是CSV来说是有意义的。 XLSX文件支持多个纸张,这意味着所有数据标记都可以在同一文件中组合。
可以使用
来实现excel
。在这种情况下,需要指定
ExcelWriter对象,因为在同一工作簿中添加了多于一张纸张。 WriteStrint redion(’logs_export.xlsx)下面
读取读数’,引擎=’XLSXWRITER’,datetime_format =’dd / mm / yyyy’,选项= {‘strings_to_urls’:false})logs_filtered.to_excel(wheriter,sheet_name =’master’,index = false)pivot1.to_excel(写字器, sheet_name =’my pivot’)writer.save()
exportin时GA大量枢轴,它有助于通过在字典中存储数据帧和工作表名并使用for循环来简化事物。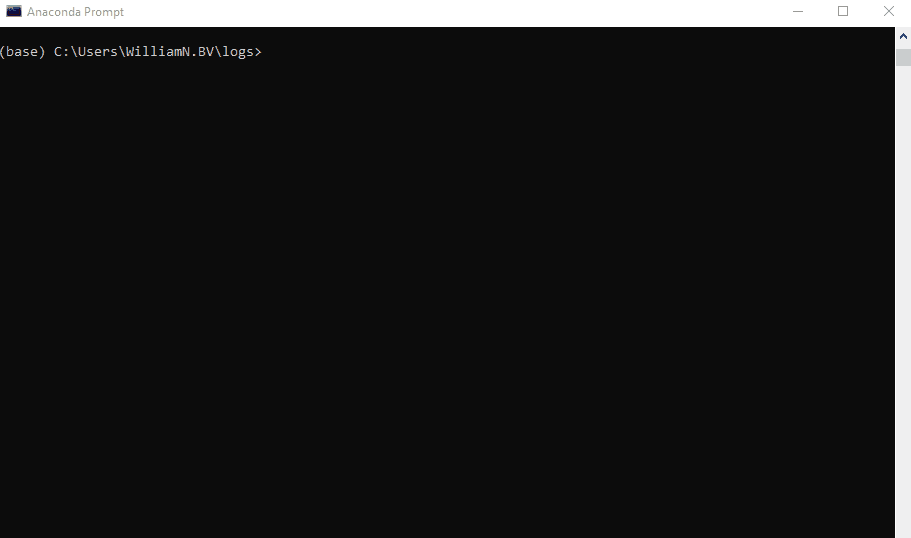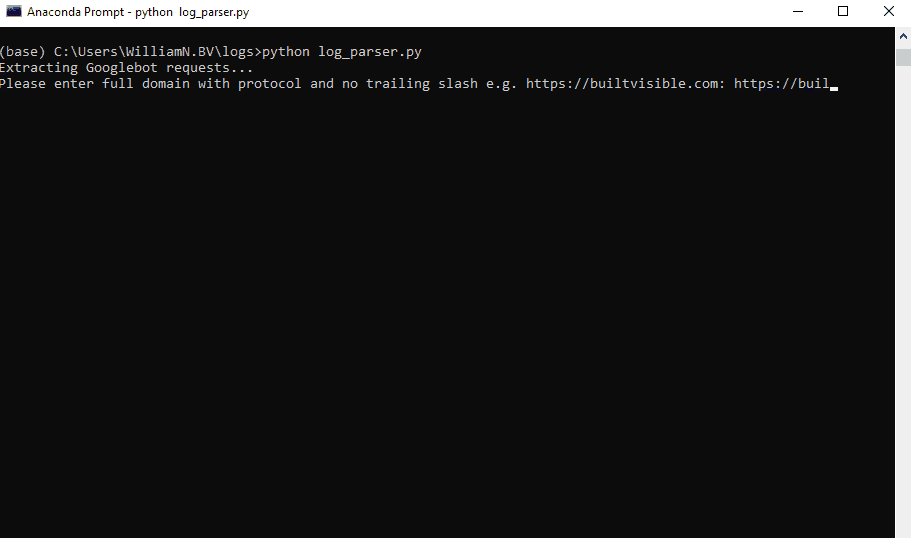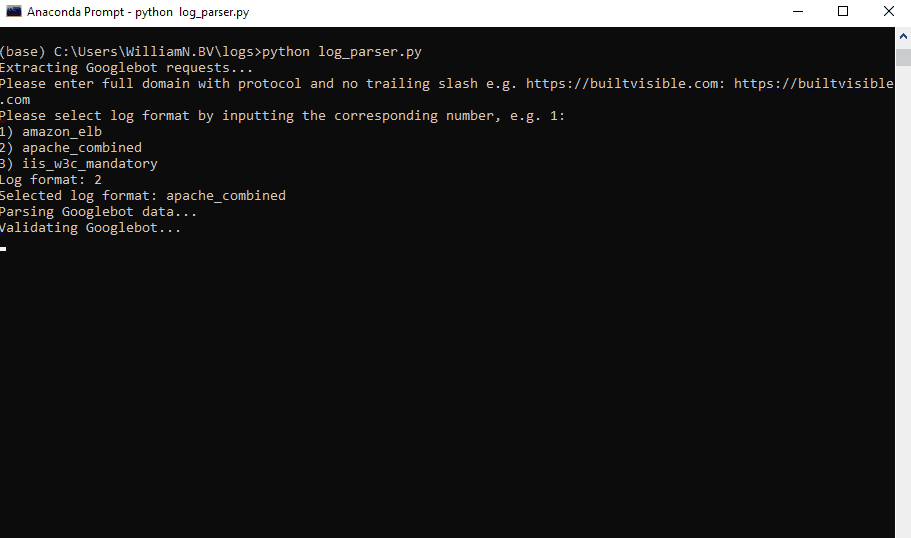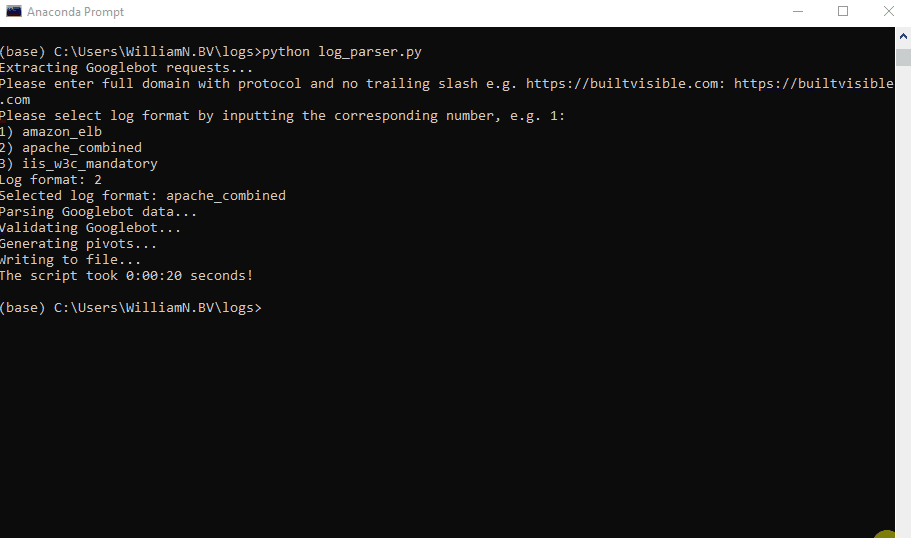
sheet_names = {‘请求状态代码每天’:status_code_date,’URL状态代码’ :status_code_url,’每天用户代理请求’:user_agent_date,’用户代理请求唯一的URL’:user_agent_url,} for工作表,sheet_names.items()中的名称:name.to_excel(writer,theper_name = photon)
最后一个并发症是,Excel的行限额为1,048,576。我们导出每个请求,因此在处理大型样品时可能会导致问题。
如果日志文件dataframe的长度大于1,048,576,则它将是将导出为CSV,防止脚本在仍然将枢轴结合到奇异的导出时失败。 如果LEN(LOGS_FILTERED)
可以从日志文件数据中收集的其他见解是值得投资的一些时间。如果您一直在避免由于所涉及的复杂性而避免利用此数据,我的希望就是这篇文章将说服您的帖子可以克服。对于那些有对编码感兴趣的工具访问的人来说,我希望突破这个过程结束,让您更好地了解创建更大脚本时所涉及的考虑因素自动化重复,耗时的任务。读数下方全脚本 I CRE可以在github上找到。
这包括其他额外的额外的额外的额外的集成,更多的枢轴,以及支持两个更大的日志格式:Amazon ELB和W3C(IIS使用)。
要以另一种格式添加,请在第17行的log_fomats列表中包含名称,并在第193行(或编辑现有的额外的Elif语句)。 当然,大规模范围将进一步扩展。保持关注的部分两篇文章,该部分将涵盖来自第三方爬虫的数据,更高级枢轴和数据可视化。读数下方更多资源:如何使用Python分析SEO数据:参考指南 8个Python库的SEO和如何使用它们 高级技术SEO:一个完全指南 图片来源 采取作者所有截图, 7月2021
