谷歌一直告诉我们多年来,他们每天看到的搜索15%他们之前没有见过。
如果有一件事我在谷歌搜索工作的15年里了解到,人们的好奇心是无穷无尽的。我们每天都看到数十亿的搜索,
和15%的查询是我们之前没有看到的 – 所以我们建立了返回结果的方法,我们无法预期。
他们已经学会了返回结果,即使他们无法预测人们会搜索的东西。
现在,图片了这个机会的意义。
如果没有人知道这些查询是,它们可能没有报告在
关键字研究工具
中,并且可能与竞争效果很少。我们可以为最有希望的那些讨厌这样的查询和写内容?让我们找出答案!
这是我们的技术计划。我们要去:
从Google Search Console获取一年的搜索查询数据。在数据的最后一天中的查询中,过滤先前未知的查询.try以先前的方式使用先前的未知查询。这将有助于我们估计其对高流量内容生产的潜力.Fimberform预测,优先考虑最有前途的想法。
自动获取Google Search控制台数据的前往下降读数
我们需要完成一些初步设置要从Python访问Google搜索控制台。
首先,我们需要下载Client_id.json文件来从我们的Pytho引用它n代码:
在Compute引擎中激活搜索控制台API
https://console.cloud.google.com/apis/api/webmasters.googleapis.com/overview?project=&folder=&organizationid=
创建新凭据/帮助我选择(搜索控制台API,其他UI,用户数据)
https://console.cloud.google.com/apis/credentials/wizard?api=iamcredentials/wizard .googleapis.com&project =
下载client_id.json 让我们安装这个库
这个库
大大简化了访问Google搜索控制台, !pip安装git + https:/ /github.com/joshcarty/google-searchConsole
你使用谷歌colab,上传client_id.json文件。 #upload client_id.jsonfrom google.colab导入filesnames = files.upload( )
您可以使用此ri获取文件上传的名称ne。
文件名=列表(names.keys.keys())[0]
现在,我们准备使用搜索控制台进行身份验证
导入searchConsoleAccount = searchconsole.authenticate( client_config = filename,serialize ='credentials.json',flow =“console”)
您需要单击提供的链接,完成身份验证步骤,并复制提供所提供的代码。
您可以打印此功能的站点列表。
打印(account.webproperties)
使用以下网站属性选择其中一个:
domain_name =“https:/ / www.sitename.com/”
[WEBPROPERTY =帐户[domain_name]
简单函数
可以拍摄Web属性并返回a Pandas数据帧,具有全年查询数据。
广告传票以下
您可以更改要获取的天数。
以下是用于获取数据的代码和输出的示例。
df = get_search_console_data(webproperty)
分离15%未知查询
当我们获取我们的搜索控制台查询数据集时,我们确保了要提取日期,允许我们轻松地执行强大的分析。
但首先,我们需要更改日期列的数据类型。
如上所述,它未自动检测为DateTime对象。
以下代码使用Pandas函数 to_dateTime 来修复该代码来修复该代码。
to_dateTime 来修复该代码来修复该代码。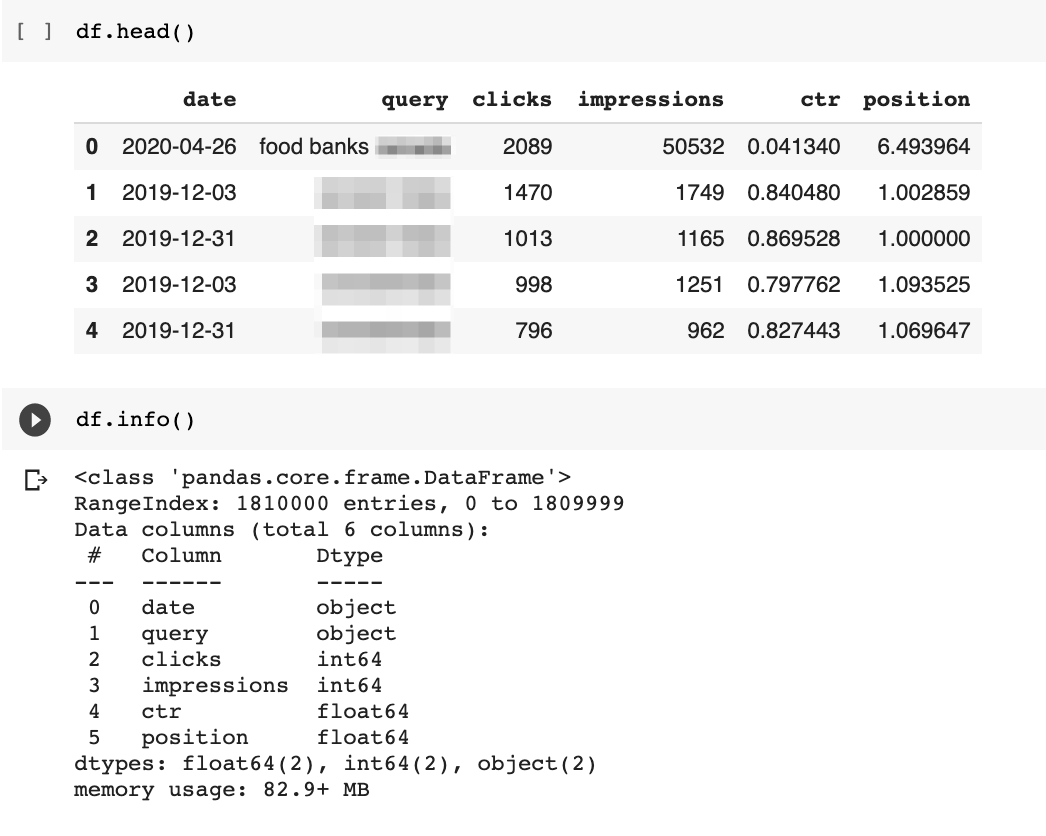 df [date“] = pd.to_dateTime( df.date)
df [date“] = pd.to_dateTime( df.date)
现在,我们现在可以缩小我们的数据集,找到每天出现的15%的未知查询谷歌可能将每日查询与所有先前已知的。
给出了我们的有限数据集,我们只会与去年中看到的查询相比。
这是我们的要执行此操作:
使用收集的数据的最后一天创建一个过滤的数据框
。搜索控制台需要几天才能更新。
创建两组唯一查询:
一个带有最后一天查询的唯一查询,另一组与去年的剩余查询。创建一组新的未知查询通过计算先前数据集之间的差异。
我数据集中的数据的最后一天是11月7.
我可以通过查找大于11月6日的日期来过滤数据帧。
超级简单!
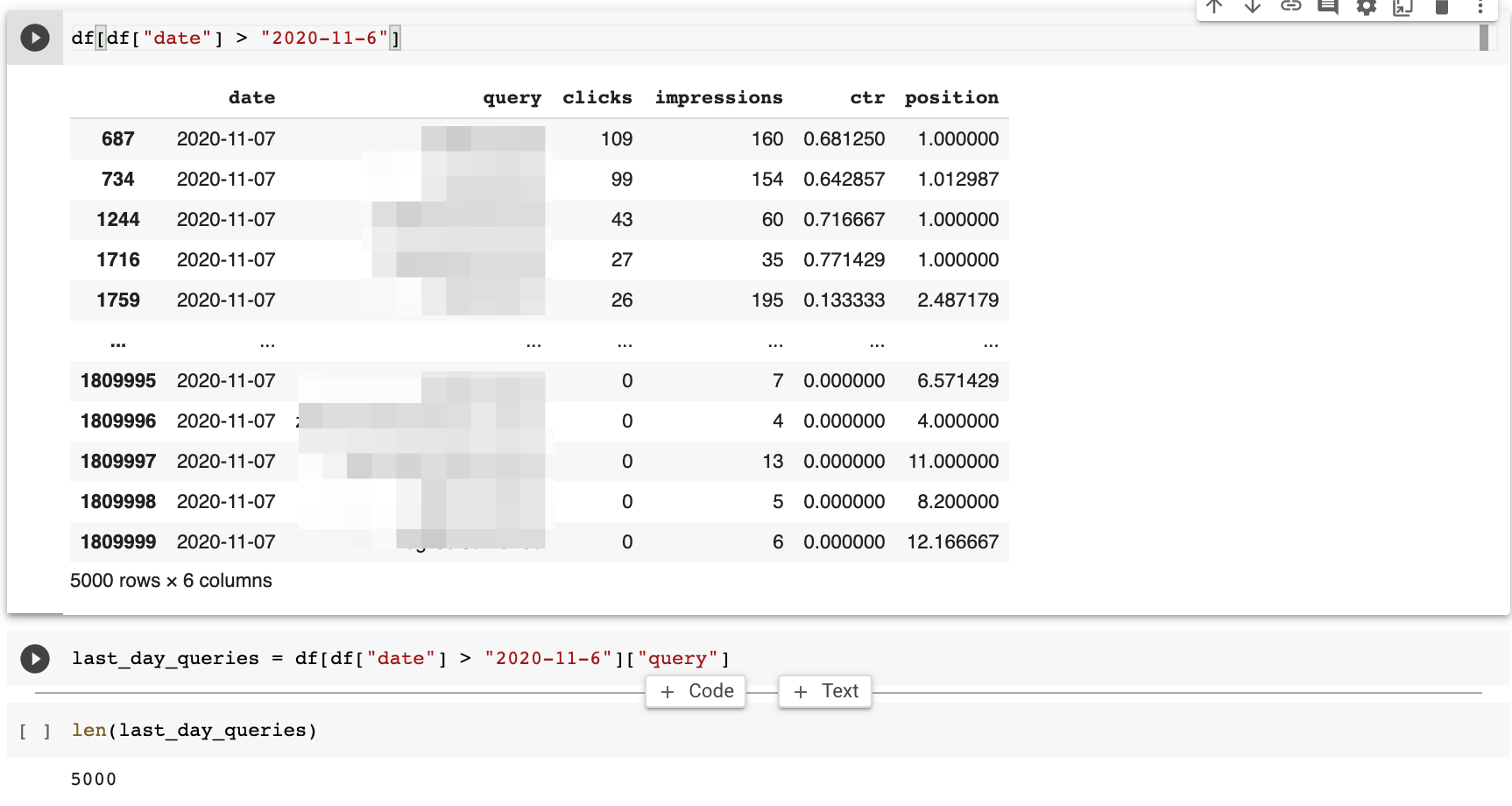
df [df [date“]>”2020-11-6“]>”2020-11-6“]
这个reTurns 5k行的查询数据。
我可以使用相同的方法来获取与其余的查询的另一个数据集。广告联接键读数下面
rest_of_queries = df [df [date]
我在我的数据集中获得180k查询。
计算未知查询非常简单,使用
python集
。
fifteen_percent = set(last_day_queries) – set(rest_of_queries)last_day_queries = df [df [date“]>”2020-11-01“] [”2020-11-01“] [”查询“]
 当我计算关键字时,我只发现212,这是当天查询的4%。
当我计算关键字时,我只发现212,这是当天查询的4%。
这不是15%,但查询的数量足以找到新的内容想法。 网站我这个分析是一个很大的非盈利,并且有趣的是手动审查未知的查询。
她e是我发现的一些查询模式。
与最近或最近引起关注的商业名称有关的查询。似乎是世界上的新闻。
让我们回顾三个例子< "2020-11-6"]["query"]
谷歌没有在我的搜索中找到这项业务,但是看谷歌确定是如何确定它是本地搜索。
可能在另一个地理位置。
在SERPS中,您可以在
下面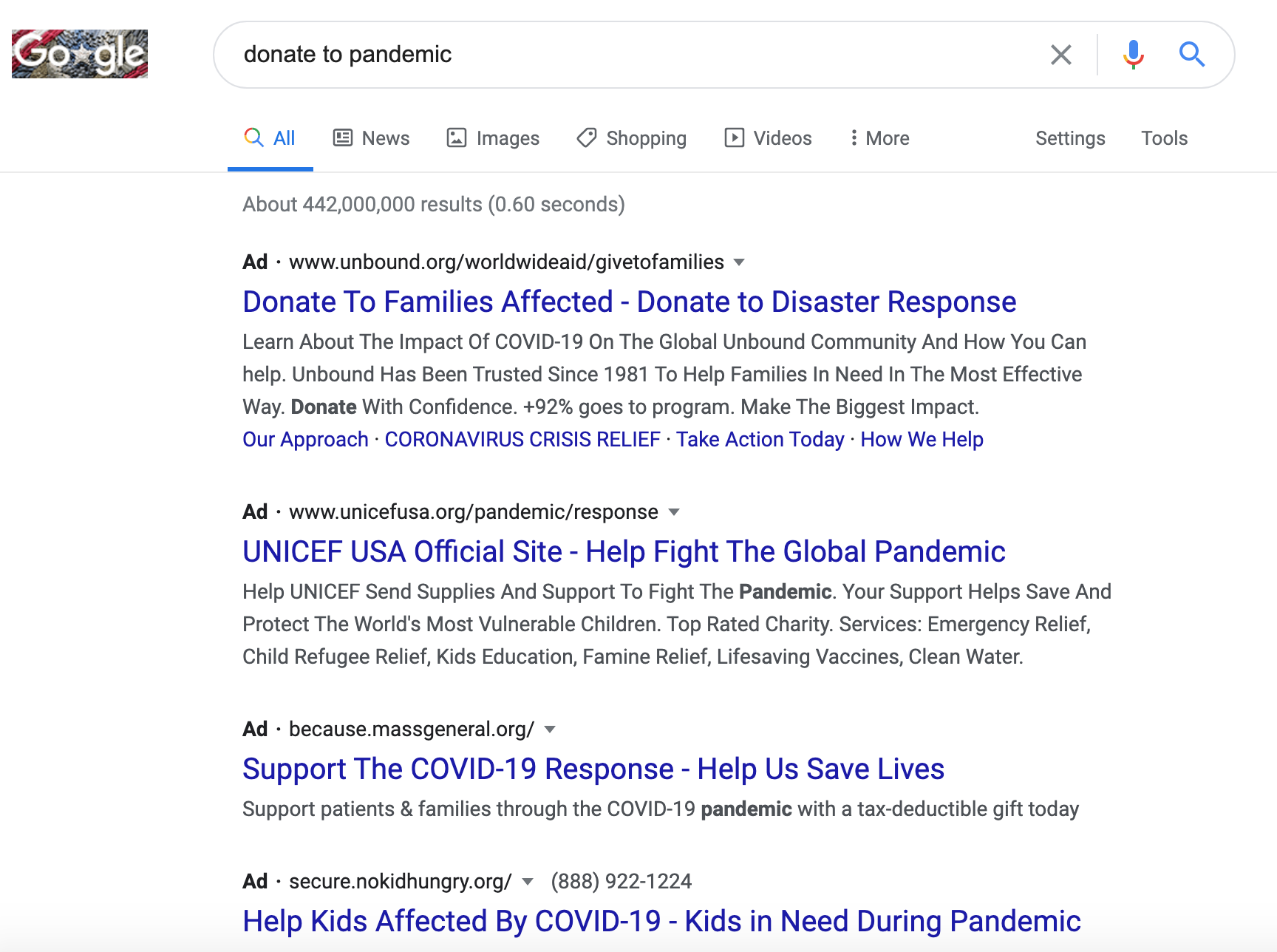 广告联系读数11月3日的新闻报道提到了BC
广告联系读数11月3日的新闻报道提到了BC
令人意义他会飙升,了解更多信息。你是否知道这种技术如何有助于发现新的内容机会?
真正强大的东西!
语义匹配查询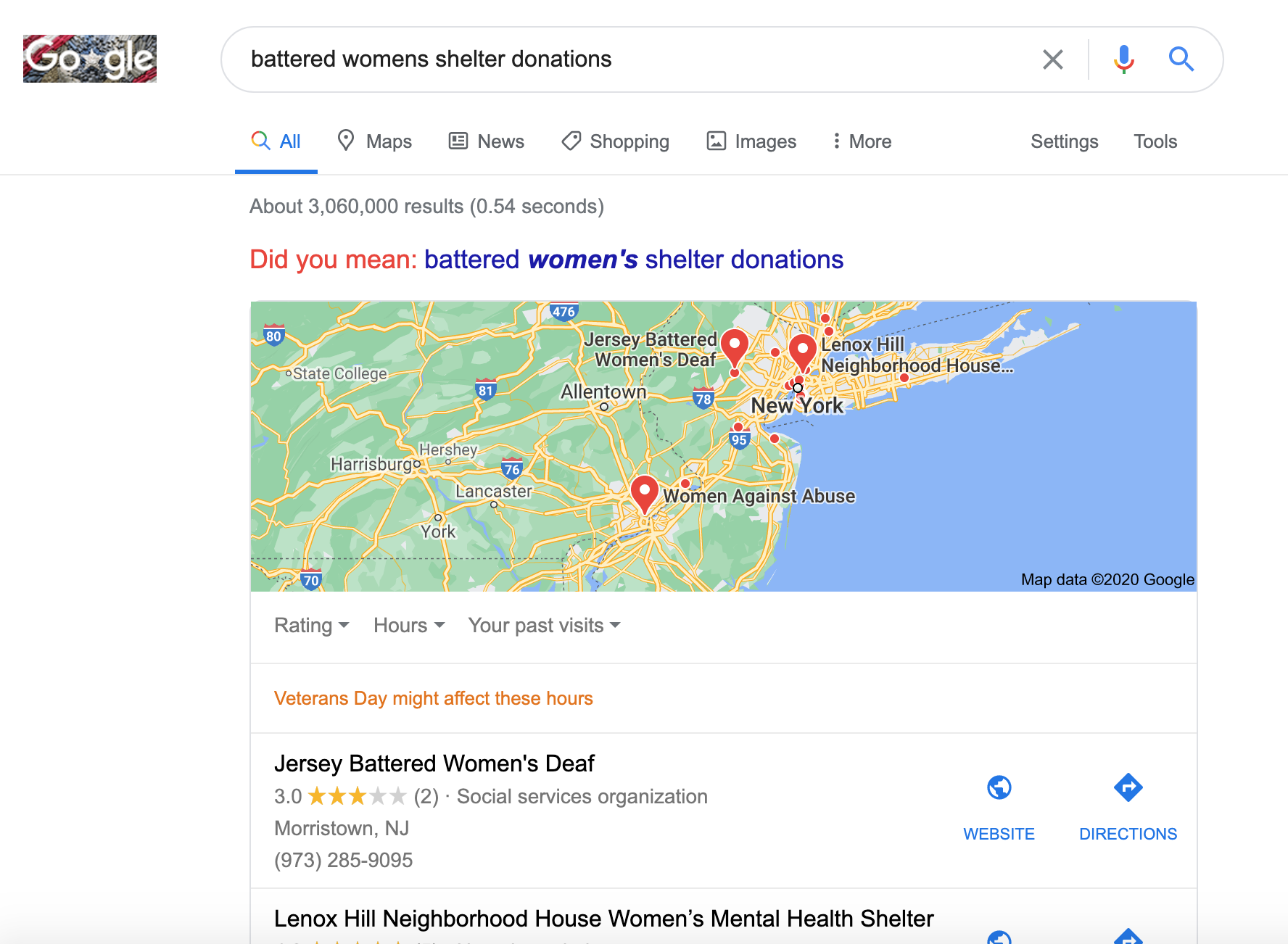
所以,我们有许多新的查询和相应的内容想法。
但是,我们没有历史表现来衡量每个机会。 因为这些查询可能从未见过之前,它们不太可能出现在关键字工具中。
我们如何知道哪些优先考虑?
这是我们可以尝试的一个聪明的技术。 我们是从Sensei 比尔Slawski的专利分析帖子
我们是从Sensei 比尔Slawski的专利分析帖子 借阅这一专利分析。
借阅这一专利分析。
他讨论的专利讨论了
规范查询
。
规范查询暗示有DupliCate方法来编写相同的搜索。
虽然专利关注语法复制,但我们可以扩展概念并考虑语义复制。
疑问,表示相同的查询,但是用不同的单词。
纸张
条例草案
覆盖了另一个采用这种方法的专利
。
但是,我们将如何检查?
使用机器学习,当然! &#129299;
的语义文本相似性是一种先进的概念,但我喜欢在简单的可视化和说明本文
它显示了一种寻找类似查询/问题的一种方法是通过他们的响应匹配它们。如果答案始终如一,我们可能会询问equIALIVENT问题!现在
读取现在
现在,让我们将这个想法翻译成Python代码。
首先,让我们安装
这个方便的库
。
!pip安装句子变换器
‘)
一旦我们有一个模型,我们将通过遵循以下过程找到语义类似的查询:将查询/句子转换为嵌入式(简化邻近计算的数字)计算查询成对之间的接近分数.Filter基于截止阈值的最接近的比赛我们可以经验确定。
在上面的屏幕截图中,您可以看看这种匹配技术有多强大。
 “新电影很棒”,“新电影如此伟大”是完美的0.98。
“新电影很棒”,“新电影如此伟大”是完美的0.98。
广告联系读数下面的分数是1. 这里是用我们的查询执行此操作的代码。首先,我们创建嵌入式。
fifteen_percent_list = list( fifteen_percent)
#compute embedding for histsembeddings1 = model.encode(fifteen_percent_list,convert_to_tensor = true)
#尝试较小的10k,因为它也是如此长时间在全套查询中运行_of_queries_list = list(set(rest_of_queries))[:10000]
embeddings2 = model.encode(rest_of_queries_list,convert_to_tensor = true)
下一个,我们想找到在语义上类似的查询与新的未知查询密切匹配的iStorical列表。 #compute cooSine videitionscosine_scores = util.pytorch_cos_sim(embeddings1,embeddings2)
最后,以下是过滤类似查询的代码。
#Output在范围内使用它们的分数(Len(fifteen_percent_list)):score = casine_scores [i] [i]如果得分> 0.7:print(f“{i}。{fifteen_percent_list [i]}
{rest_of_queries_list [i]} \ n}}}} \ nscore:{score:.4f}“)
我只能检查10,000个查询,没有匹配0.5以上。
我稍后会尝试使用完整的数据集并在Twitter上报告结果。
请随时举报您在实验中获得的内容。
优先考虑最有希望的想法
当我在视觉检查未知的疑问,我und几个有趣的模式值得进一步调查。
筹款思想和我附近的另一个关于
使用数据驱动方法来评估每个人对可视化和预测的潜在影响。
首先,我将创建两个过滤的数据帧,其中查询包含模式关键字。
想法= df [df [‘查询’]。str.Contains(“想法”)]
relat_me_df = df [df [‘查询’]。str.Contains(“靠近我”)] 我们将将日期列设置为数据帧的索引。广告联交影读数下方这将使我们能够在几天或几个月内执行高级分组。
Ideas_df = Idears_df.set_index(“日期”)
resp_me_df = acd_me_df.set_index(“日期”)
您可以看到日期不再包含在列的列表。
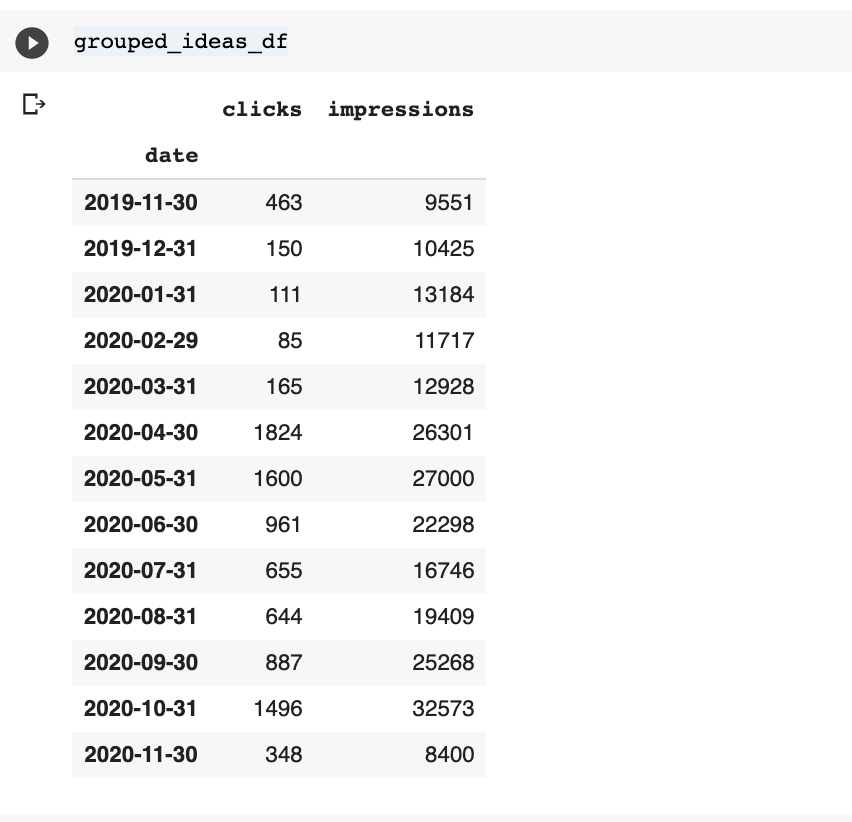
让我们组中的两个数据集由月份和可视化它们。
以下是“想法”数据集的代码。
grouped_ideas_df = teams_df.groupby(pd.grouper(
freq =’m’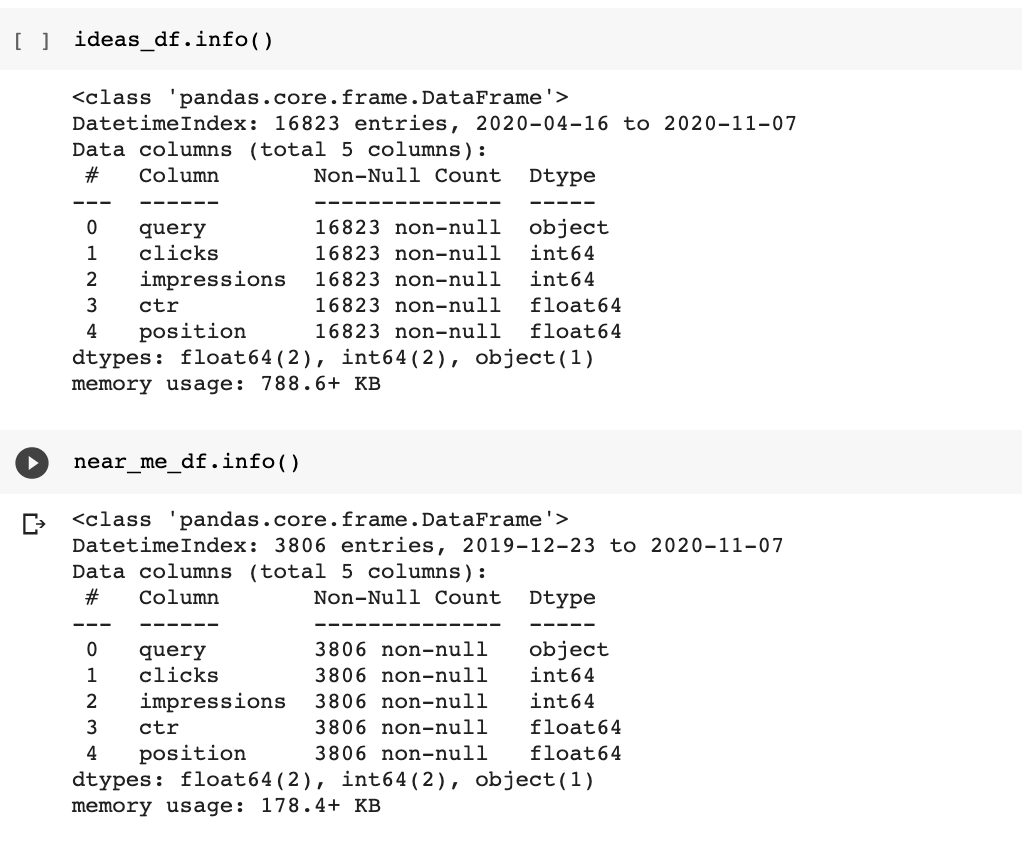 ) ).sum()[[点击“,”印象“]]
) ).sum()[[点击“,”印象“]]
我以粗体字母突出显示了强大的熊猫类, Gouger,,它能够通过日期进行高级分组。
M
M
M
代表月末端频率。
下面
的广告联系读数我们也使用
D ,该读数是日历日频率。
您可以在此处找到完整的列表时间序列频率别名
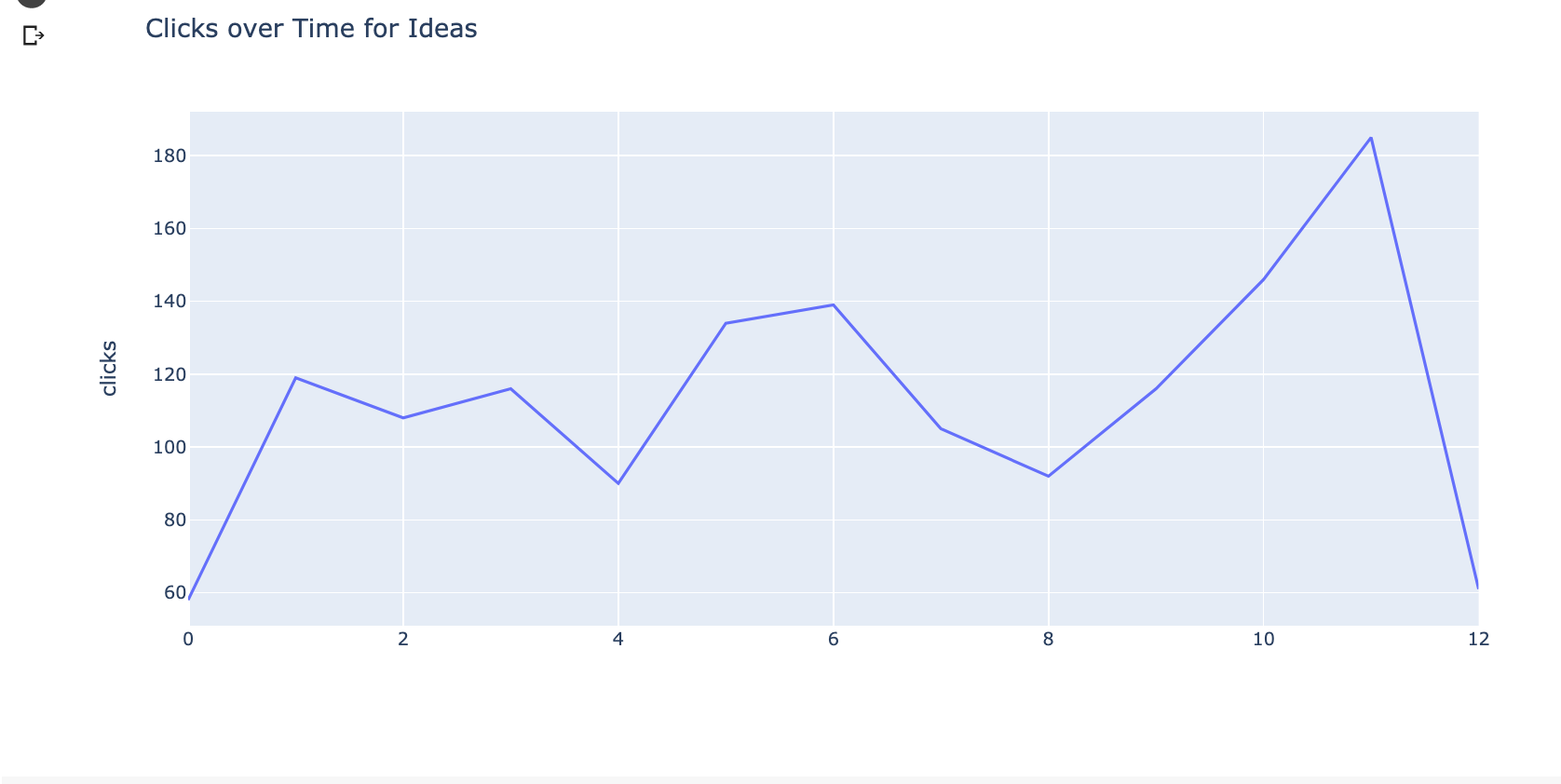
现在,让DataSets绘制他们的历史表现。 [1图23是
我们将使用
绘图文库来执行此操作。
绘图地.Express作为PX
图= px.line(grouped_ideas_df,Y = “点击”,标题= ‘点击次数随时间的想法’)
fig.show()
这是积近我的查询。
这些可视化清楚地表现出对两个机会的需求增加,但我们可以更好地做得更好,并尝试预测来看未来的内容影响可能是。
每月数据点太少,以构建预测模型。
下面
的广告联系读数让我们将频率增加到几天。
[以下是绘图与日常数据的样子。
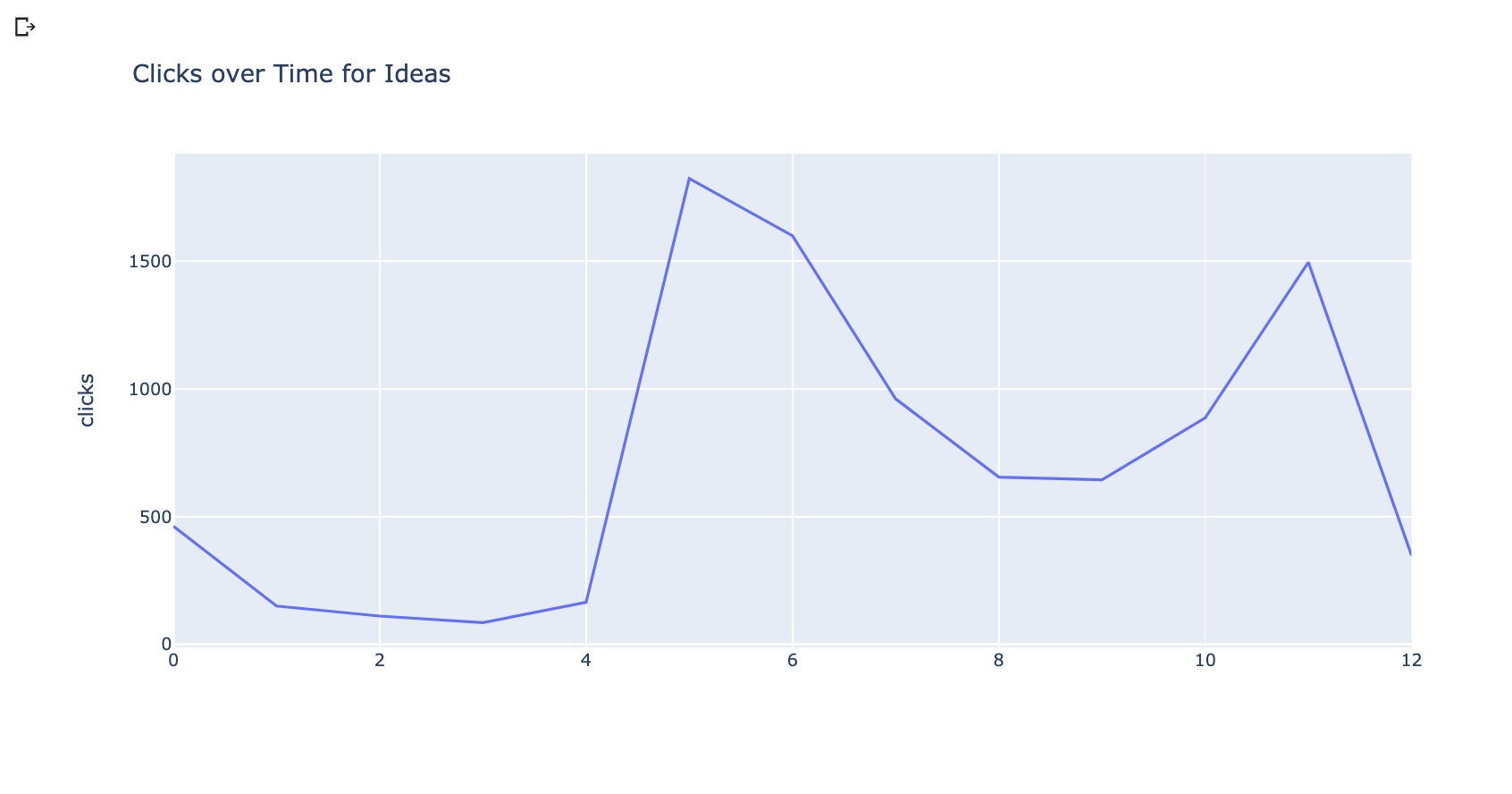
一旦我们在白天分组,我们可以使用[Facebook先知库预测点击几天到未来。
我们将使用最近的代码来自我的团队的Python Twitor。
我们回到另一个
#rstwittorial
星期四! &#128588;今天,我们正在学习使用
的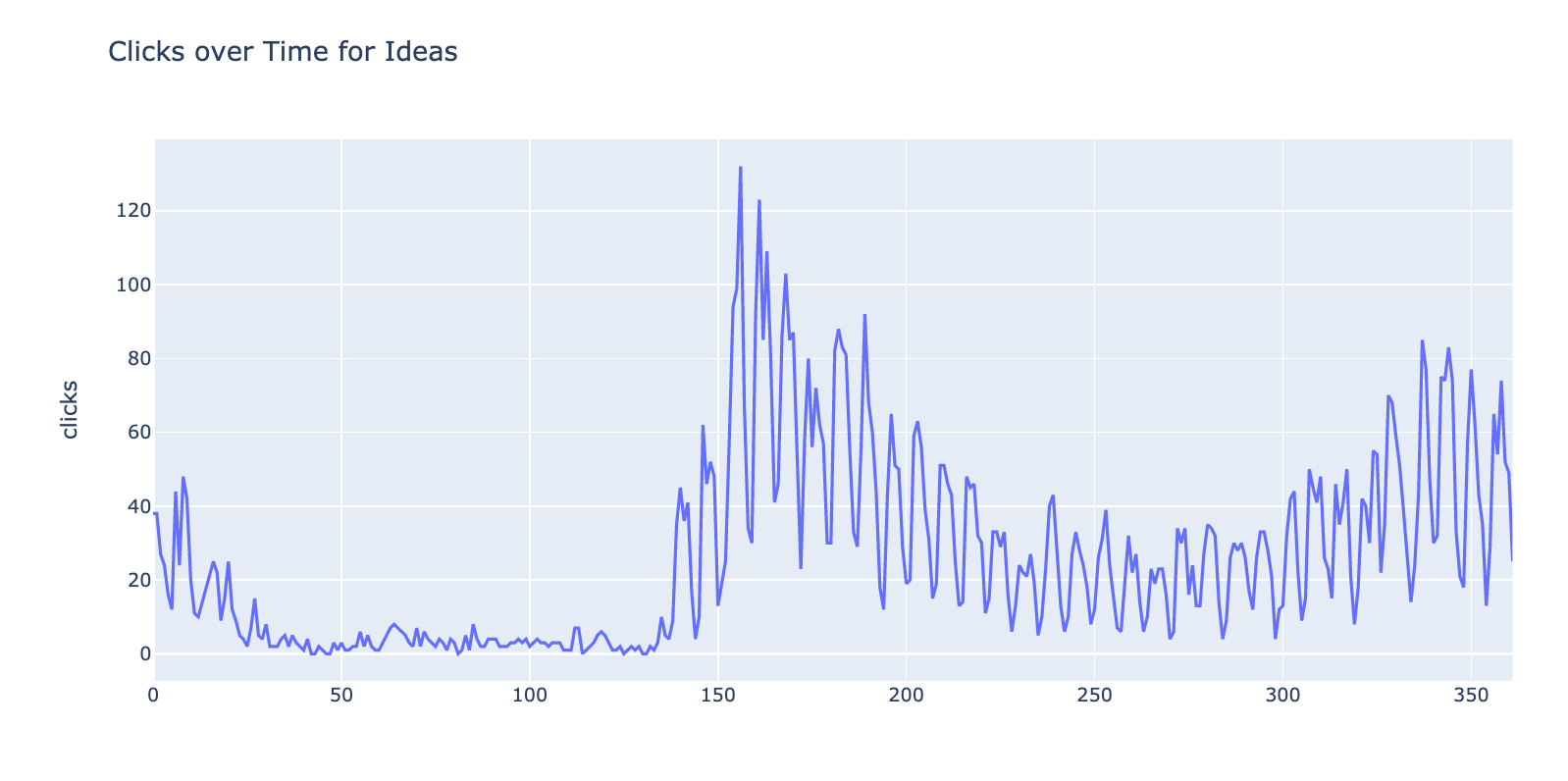 #searchconsole
#searchconsole
数据&#129504; 
这是输出⬇️ pic .twitter.com / kodfdewb2e
– Ranksense(@ranksense) 10月22,2020
我们只需要重命名列以匹配库的预期。
dft = grouped_ideas_df.reset_index()。重命名(列= {“日期”:“DS”,“点击”:“Y”} )我们可以用两条线训练预测模型。 m = prophet()m.fit(dft)一旦培训了模型,我们可以预测接下来的30天。 #predicting clicks for接下来的30天.Future_30 = m.make_future_dataframe(句点= 30)预测_30 = m.predict(puffult_30)
最后,我们可以想象我们对筹款思想数据集的预测。
#visualized预测下一30 days.plot_plotly(米,forecast_30,xlabel = ‘日期’,ylabel = ‘点击次数’)
黑点表示实际数据点。暗蓝线是预测的中间点,浅蓝色频段是不确定性。
广告联系读数以下
您可以看到模型正在尝试要适应模式中的点数,但它无法适应大的异常值5月周围。
今年很多事情都是不可预测的,所以这里没有惊讶。
在实践中,当你有一个至少几年的数据集时,预测会显着改善。
最后一步是根据最佳流量潜力预测几个候选想法的流量,总结一下,并基于最佳流量潜力来排名思路。
资源学习更多
最好的学习方式是通过做。您可以使用我涵盖的所有步骤找到谷歌Colab笔记本
我鼓励您尝试并报告您与ME学习的内容
在Twitter
&#128013 ;&#128293;
