谷歌AI博客宣布了Kelm,一种方法可以用于减少搜索中的偏见和有毒内容(
开放式域问题回答)。它使用一种名为Tekgen的方法将知识图事实转换为自然语言文本,然后可以用于改善自然语言处理模型。
什么是Kelm?
Kelm是知识的首字母缩写 – 增强语言模型预培训。像BERT这样的自然语言处理模型通常在网站和其他文件上培训。 KELM提出向语言模型预培训添加值得信赖的事实内容(知识增强型
),以提高事实准确性和减少偏差。
Tekgen将知识图形结构数据转换为自然语言称为kelm语料的文本
 Kelm使用值得信赖的数据 谷歌研究人员建议使用知识图表提高事实学准确性,因为它们是一个值得信赖的事实来源。读数下方
Kelm使用值得信赖的数据 谷歌研究人员建议使用知识图表提高事实学准确性,因为它们是一个值得信赖的事实来源。读数下方
“替代来源信息是知识图(kgs),由结构化数据组成。 kgs本质上是,因为这些信息通常从更多可信的源中提取,后处理过滤器和人工编辑器确保了不恰当和不正确的内容。“
使用kelm是google?
谷歌尚未指示Kelm是否正在使用中。 Kelm是一种语言模型预培训的方法,它表现出强烈的承诺,总结在谷歌AI博客上。
偏见,事实准确性和搜索结果
CompentiNG对研究论文此方法提高了事实学精度:
“它带来了改善了事实精度的进一步优点,并在所产生的语言模型中减少毒性。
这个研究很重要,因为减少偏差和增加的事实准确性
可以影响网站的排名方式。
但是直到凯尔姆在使用中,就无法预测它会有什么样的影响。
谷歌目前没有事实检查搜索结果。
Kelm应该引入,可以想到对促进事实不正确的陈述和想法的地点产生影响。
广告联系读数kelm 可能影响超过搜索
Kelm Corpus已在Creative Commons许可下释放e(
cc by-sa 2.0
理论上
,任何其他公司(如Bing,Facebook或Twitter)可以使用它来改善他们的自然语言处理预训练。
这是可能的那么Kelm的影响可能会跨越许多搜索和社交媒体平台。间接与妈妈的关系[谷歌还表明,在谷歌满足偏差不会对其给出的答案感到负面影响之前,将不会释放下一代Mum算法。
“正如我们仔细测试了自2019年以来发起的伯爵的许多应用一样,妈妈将经历相同的过程,因为我们在搜索中应用这些模型。具体而言,我们’ll寻找patteRNS可以指示机器学习中的偏见,以避免将偏差引入我们的系统。“
kelm方法专门针对偏差减少,这可以使其有助于开发迁移算法。
机器学习可以产生偏见的结果
研究论文指出,像BERT和GPT-3这样的自然语言模型用于训练的数据可能导致“
有毒内容
”和偏见。
在计算中,有一个旧的缩写,吉茄代表垃圾 – 垃圾出来。这意味着输出的质量由输入的质量决定。
如果您培训的是高质量的算法,那么结果将是高质量的。
研究人员提出的是提高质量伯特和妈妈等技术的数据训练,以便去除偏差。
知识图
知识图是一种以结构化数据格式的事实集合。结构数据是一种标记语言,以通过机器容易消耗的方式传达特定信息。
在这种情况下,信息是关于人,地方和事物的事实。
谷歌知识2012年推出了图表
作为帮助谷歌了解事物之间的关系的一种方式。因此,当有人问华盛顿时,谷歌就可以辨别出询问的人询问华盛顿人,哥伦比亚的州,州或地区。
谷歌的知识图表是公开的
广告由来自事实的可信源的数据组成。
谷歌的2012年宣布将知识图表描述为建立下一代搜索的第一步,我们目前正在享受。
知识图形和事实精度
知识图表数据用于本研究论文中用于改进谷歌的算法,因为信息是值得信赖和可靠的。
谷歌研究论文提出将知识图信息集成到培训过程中消除偏差并提高事实精度。
谷歌研究提出的是两倍。
首先,他们需要将知识库转换为自然语言文本。第二个结果语料库,名为知识增强的语言模型Pre-Tra然后可以将(KELM)集成到算法预训练中以减少偏差。
研究人员解释如此:
“”大型预先训练自然语言处理(NLP)模型,如BERT,ROBERTA,GPT-3,T5和REARM,利用来自Web的自然语言语言,并在特定于任务数据上进行微调
然而,自然单独的语言文本表示知识的有限覆盖范围,此外,文本中的非事实信息和有毒内容的存在最终可能导致所产生的模型中的偏差。“从知识图形结构数据中读数以下
广告自然语言文本
研究人员说明将知识库信息集成到T中的问题Raining是知识库数据的形式是结构化数据的形式。解决方案是使用称为数据到文本生成的自然语言任务将知识图形结构转换为自然语言文本。 他们解释说,因为数据到文本生成是挑战的,他们创建了他们所谓的新“管道
”
文本来自kg生成器(tekgen)
“解决问题。
引文:
知识图基于知识增强语言模型的合成语料库生成预训练
(PDF)
Tekgen自然语言文本提高了事实准确性
Tekgen是研究人员创建的技术,以将结构化数据转换为自然语言文本。这是一个最终结果,firmuAl Text,可用于创建Kelm语料库,然后可以用作机器学习预培训的一部分,以帮助防止偏见进入算法。
研究人员指出,添加了这种额外的知识图信息(Corpora)进入训练数据导致了完善的事实精度。
Tekgen / Kelm纸张展示:
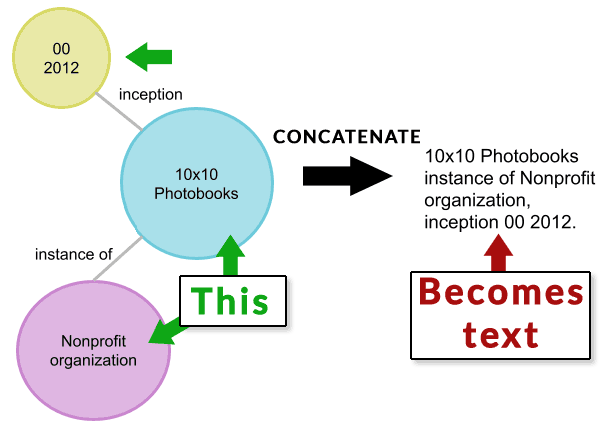
“”我们进一步展示类似于Wikidata的全面封面,百科全书的百科全书可以用于整合结构化的KGS和自然语言语言。 …我们的方法将kg转换为自然文本,允许它无缝地集成到现有的语言模型中。它具有改善的事实精度和降低毒性的进一步优点E结果语言模型。“ Kelm文章发表了一个图示,显示一个结构化数据节点如何连接,然后从那里转换为自然文本(语言化)。 我分手了例证分为两部分。
以下是表示知识图形结构化数据的图像。数据被级联到文本。
TEKGEN的第一部分的屏幕快照转换处理
下面的图像表示Tekgen进程的下一步,它采用连接文本并将其转换为自然语言文本。
文本的屏幕截图转向自然语言文本
存在其他插图,显示如何生成可用于预训练的Kelm自然语言文本。 Tekgen纸显示该图示加上说明:

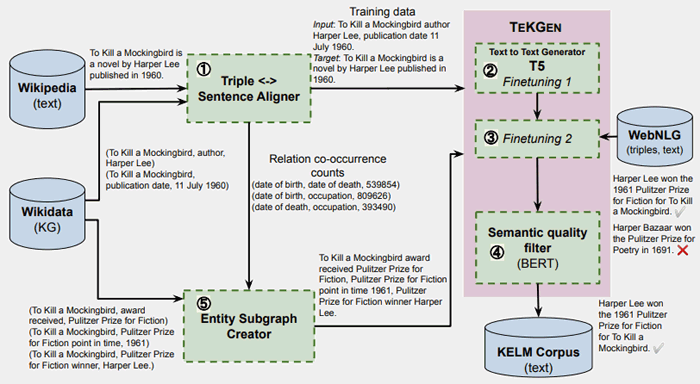
“在步骤1中,使用远程监管的kg三元脉。在步骤2和3,在该语料库上首先顺序地精细调整T5,然后依次进行微调Webnlg语料库上的少量步骤,在步骤4中,伯特被微调,以为生成的句子产生语义质量分数Triples.Steps 2,3和4一起形成Tekgen.Tekgen.Te生成Kelm语料库,在步骤5中,使用来自步骤1中生成的训练语料库的关系对对齐计数来创建实体子图。然后转换子图三级进入自然文本使用tekgen。“
kelm读取的广告联系读数kelm努力减少偏见并促进准确性
在谷歌的AI博客上发表的Kelm文章,即Kelm具有现实世界的应用,特别是对于问题回答任务明确地与信息检索(搜索)和自然语言处理(像BERT和MUM等技术)。谷歌研究了很多事情,其中一些似乎是探索可能的,但似乎似乎是死亡。可能不会进入谷歌的算法的研究通常会结束,因为该技术不能以一种方式实现更多的研究。 但是与kelm并非如此和tekgen研究。这篇文章在关于真实世界的发现态度乐观态度。这倾向于给予它更高的概率,即Kelm最终将其以一种形式地搜索。
“”这具有关于知识密集型任务的现实世界应用,例如问题应答,提供事实知识至关重要。此外,这种Corpora可以应用于大型语言模型的预培训,并且可能会降低毒性和改善事实。“ 读数下方将在很快使用Kelm? 谷歌最近宣布了妈妈算法需要准确性,为KELM语料库创建的东西。但Kelm的应用是不限于妈妈。减少偏见和事实准确性是当今社会的关键问题,研究人员对结果持乐观态度倾向于使其在某种形式中使用的更高概率在搜索中的未来。 谷歌AI文章关于kelm 与语言模型,与语言模型进行集成的知识图 kelm研究纸(PDF) 基于知识增强语言模型的知识图的合成语料库生成预训练 Tekgen训练在Github的语料库
