搜索意图有很多了解,通过使用深度学习通过分类文本和使用自然语言处理(NLP)技术(NLP)技术分解SERP标题来进行搜索意图 基于语义相关性的聚类与解释的好处。 我们不仅知道解密搜索意图的好处 – 我们也有许多技术进行规模和自动化。
但是,但通常,那些涉及构建自己的AI。如果您没有时间,如果您的知识?
在此列中,您将学习通过使用Python的搜索意图自动化关键字聚类的逐步过程。
广告联系读数下方
SERPS包含搜索意图的见解
一些方法r否认您将所有副本从排名内容的标题获取给定关键字,然后将其汇入神经网络模型(您必须建立和测试),或者您可以使用NLP到群集关键字。
还有另一种方法使您可以使用Google非常自身的AI对您进行工作,而无需刮掉所有SERP内容并构建AI模型。
让我们假设谷歌排名站点URL通过满足用户查询以降序满足用户查询的可能性。因此,如果两个关键字的意图是相同的,则SERP可能是相似的。
广告联网读数在下面
多年来,许多SEO专业人员比较了
关键词
的SERP结果进行了推断共享(或共享)的搜索意图留下来核心更新之上,所以这不是什么新的。
这里的值加载是这种比较的自动化和缩放,提供了速度和更高的精度。
以CSV下载的SERPS开始缩放意图。
1。将列表导入Python Notebook。
将熊猫导入pdimport numpy作为npserps_input = pd.read_csv(’data / sej_serps_input.csv’)del serps_input [‘未命名:0’] serps_input
下面是现在导入到一个数据帧熊猫SERP中的文件。
2。 Filter数据(Page 1 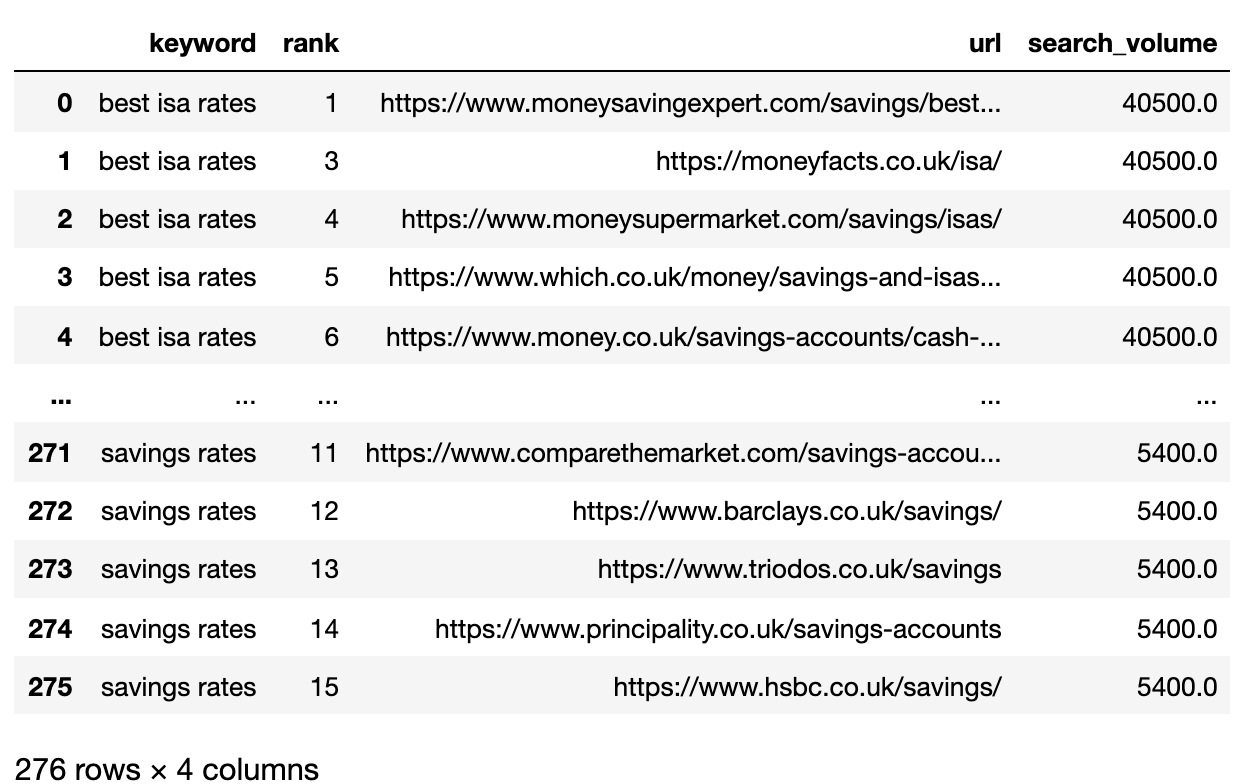
我们想比较关键字之间的每个SERP的Page 1结果。 我们将将Dataframe拆分为Mini关键字DataFrame以运行Filtering函数在重新结交单个DataFrame之前,因为我们希望在关键字级别过滤:
#plit serps_grpby_keyword = serps_input.groupby(“关键字”)k_urls = 15#应用scromentef filter_k_urls(group_df):filtered_df = group_df .loc [group_df [‘url’]。notnull()] filtered_df = filtered_df.loc [filtered_df [‘等级’]
3。将排名URL转换为字符串
因为有更多的SERP结果URLS,我们需要将这些URL压缩成单行以表示关键字的SERP。
这里是如何:<= k_urls] return filtered_dffiltered_serps = serps_grpby_keyword.apply(filter_k_urls)# Combine## Add prefix to column names#normed = normed.add_prefix('normed_')# Concatenate with initial data framefiltered_serps_df = pd.concat([filtered_serps],axis=0)del filtered_serps_df['keyword']filtered_serps_df = filtered_serps_df.reset_index()del filtered_serps_df['level_1']filtered_serps_df
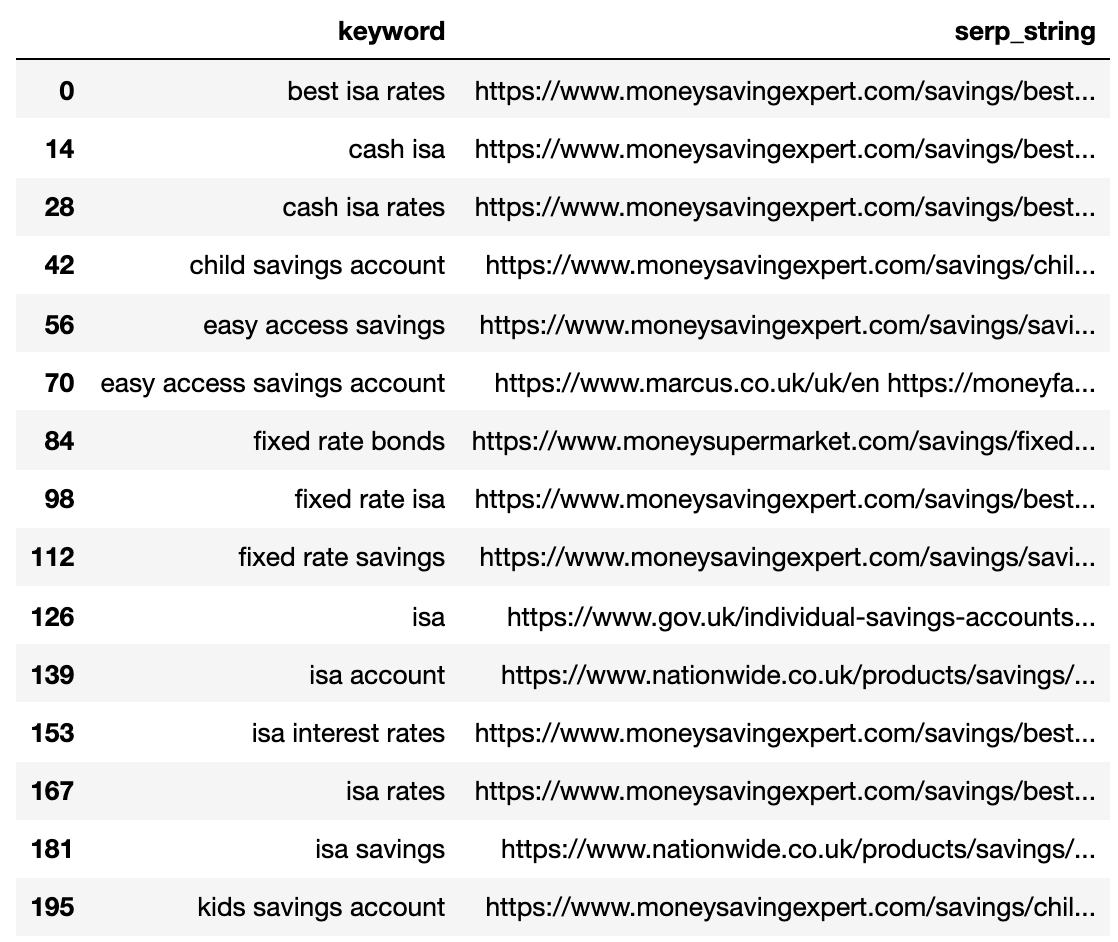
#将结果转换为使用分割应用Combinefiltserps_grpby_keyword = filtered_serps_df.groupby( “关键字”)的字符串DEF string_serps(DF):DF [ ‘serp_string’] = ”。加入(DF [ ‘URL’])返回DF#Combinestrung_serps = filtserps_grpby_keyword。应用(string_serps)#与初始数据帧和cleanstrung_serps = pd.concat([strung_serps],xach = 0)strung_serps = strung_serps[[‘关键’,’serp_string’]#。head(30)strung_serps = strunm_serps.drop_duplicates ()下面Strung_serps
显示了每个关键词压缩成单线的SERP。

6。比较SERP相似性
要执行比较,我们现在需要每个关键字SERP的每个组合都与其他对配对:
#
#对齐SERPSDEF SERPS_ALIGN(K,DF):PRIME_DF = DF。 loc [df.keyword == k] prime_df = prime_df.rename(列= {serp_string“:”serp_string_a“,’关键字’:’关键词’})comp_df = df.loc [df.keyword!= k] .reset_index (drop = true)prime_df = prime_df.loc [prime_df.index.repeat(len(comp_df.index))]。reset_index(drop = true)prime_df = pd.concat([prime_df,comp_df],axis = 1)prime_df = prime_df.rename(列= {serp_string“:”serp_string_b “,’,’关键字’:’关键字_b’,”serp_string_a“:”serp_string“,’关键字’:’关键字’})return prime_dfcolumns = [‘关键字’,’serp_string’,’serp_string_b’] matched_serps = pd .dataframe(列=列)matched_serps = matched_serps.keelna(0)查询= strunm_serps.keyword.to_list()查询中的q:temp_df = serps_align(q,strung_serps)matched_serps = matched_serps.append(temp_df)matched_serps 
以上显示了所有关键词SERP对组合,使其准备好进行SERP字符串比较。
没有开源比较列表对象的库s按顺序,所以函数已在下面为您编写。
函数'serp_compare'读数比较了站点的重叠和serps之间的这些站点的顺序。
导入py_stringmatching作为smws_tok = sm.whitespacetokenizer()#只比较顶部k_urls结果def serps_simillity(serps_str1,serps_str2,k = 15):denom = k + 1 norm = sum([2 *(1 / i – 1.0 /(endom))对于i在范围内(1,endom)])ws_tok = sm.whiteSpacetokenizer()serps_1 = ws_tok.tokenzize(serps_str1)[:k] serps_2 = ws_tokenzize(serps_str2)[:k]匹配= lambda a,b:[ B.Index(x)+1如果x在b else none的x中的x在a] pos_intersections = [(i + 1,j)I,j在枚举中(匹配(serps_1,serps_2))如果j不是none] pos_in1_not_in2 = [I + 1对于i,j中的i,emumerate(匹配(serps_1,serps_2))如果j为none,则pos_in2_not_in1 = [i + 1对于i,emumente(serps_2,serps_1))如果j为none] a_sum = sum([abs(1 / i -1 / j)对于i,j在pos_intersections中,b_sum = sum(在pos_in1_not_in2中的i中的[abs(1 / i -1 / denom))c_sum = sum(在pos_in2_not_in1中的i中的[abs(1 / i -1 / denom)])) Intent_prime = a_sum + b_sum + c_sum intent_dist = 1 – (intent_prime / rang)return intent_dist#应用upoundmatched_serps [‘si_simi’] = matched_serps.apply(lambda x:serps_similarity(x.serp_string,x.serp_string_b),axis = 1) matched_serps[[ “关键字”, “keyword_b”, “si_simi”]]
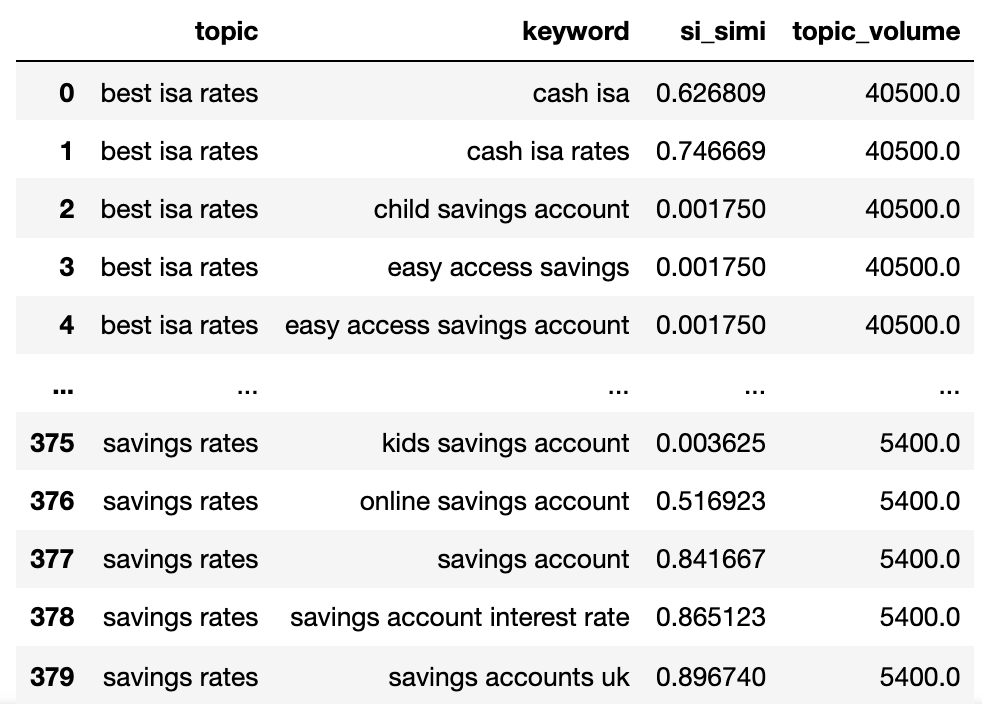
现在,比较已被执行时,我们可以启动群集关键字。
下面
的广告传票读数我们将处理具有加权的任何关键字相似之处为40%以上。
通过搜索intentsimi_lim = 0.4#join search startumekysv_df = serps_input[[‘xecky’,’search_volume’]]。drop_duplicates()keysv_df.head()#附加主题volskeywords_crossed_vols = serps_compared.merge(keysv_df,on =’关键字’,how =’left’)关键词_crossed_vols.renamame(columns = {‘关键字’:’主题’,’关键字_b’:’关键字’,’search_volume’:’ topic_volume’})#sim si_simikeywords_crossed_vols.sort_values(’topic_volume’,ascending = false)#tred nanskeywords_filtered_nonnan = wessions_crossed_vols.dropna()关键词_filtered_nonnan
我们现在拥有潜在的主题名称,关键词serp相似度和搜索卷每种。
您将注意到,关键字和关键字分别已重命名为主题和关键字。
读取下方的广告联网读数现在我们将使用LAMDAS技术迭代DataFrame中的列。
LAMDAS技术是在Pandas DataFrame中迭代行的有效方法,因为它将行转换为列表,而不是与.iterrows()函数相反。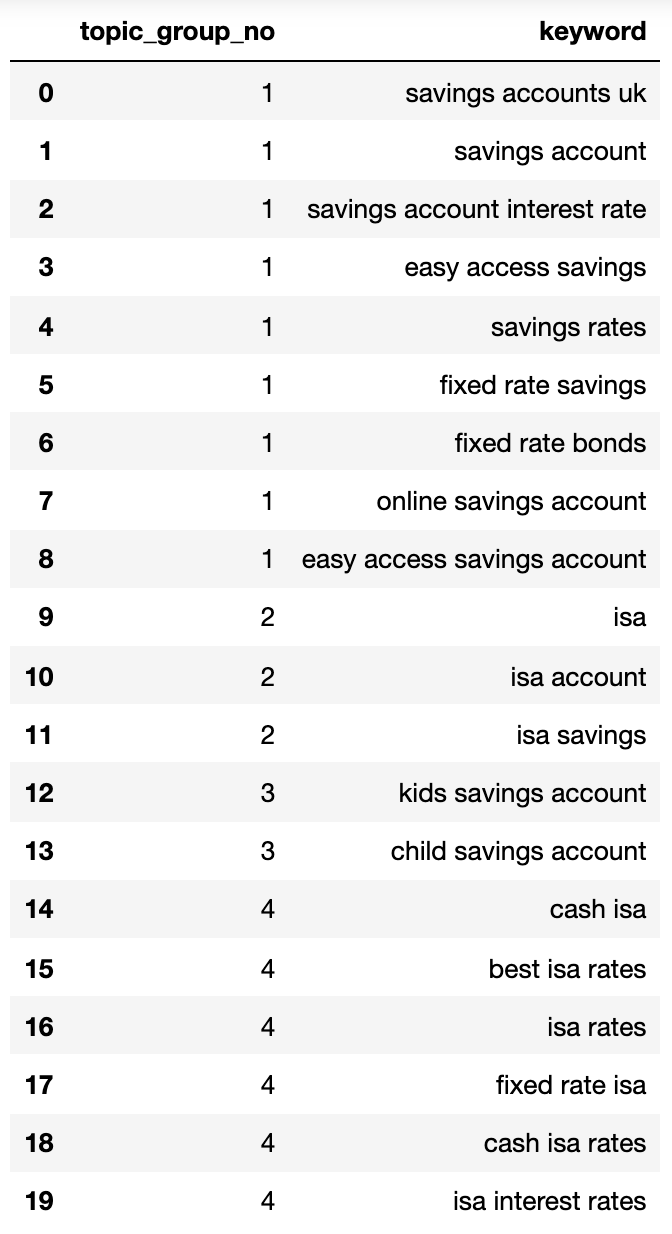 此外
此外
queries_in_df = list(set(confordys_filtered_nonnan.topic.to_list()))topic_groups_numbered = {topics_added = [] def find_topics(si,keyw,topc):i = lode_index(topic_groups_numbered)if(si> = simi_lim)和(不是topics_added的keyw)和(不是topics_added的topc):i + = 1 topics_added.append(keyw)topics_added.append(topc)主题_gROUPS_NUMBERED [i] = [keyw,topc] elif si> = simi_lim和(topics_added中的keyw)和(topics_added中的topc):j = [key for key,topic_groups_numbered的值.Items()如果键键值,则topics_added。附加(topc)topic_groups_numbered [j [0]]。Append(topc)elif si> = simi_lim和(topics_added的topics中的keyw)和(topics_added in topcded):j = [key for key,topic_groups_numbered.items()如果Topc In Value] topics_added.append(keyw)主题_groups_numbered [j [0]]。附加(keyw)def apply_impl_ft(df):return df.applet(lambda行:find_topics(row.si_simi,tow.keyword,whee.topic) ,轴= 1)apply_impl_ft(关键字_filtered_nonnan)topic_groups_numbered = {k:list(set(v))for k,v在topic_groups_numbered.items()} topic_groups_n中下面的umbered 显示了包含由搜索意图聚集到编号组的所有关键字的字典: {1:[‘固定速率ISA’,’ISA率’,’ISA利率’, “最佳ISA率”,“现金ISA”,“现金ISA率”,2:[“儿童储蓄账户”,“儿童储蓄账户”,3:[“储蓄账户”,“储蓄账户利率”,“储蓄率’,“固定利率储蓄”,“易于访问储蓄”,“固定利率债券”,“在线储蓄账户”,“易于访问储蓄账户”,“储蓄账户”,4:[“ISA账户”, ‘ISA’,’ISA储蓄’]} 让我们坚持到Dataframe:主题_groups_lst = []对于t主题_groups_numbered.items():对于l:topic_groups_lst .append([k,v])topic_groups_dictdf = pd.dataframe(topic_groups_lst,columns = [‘topic_group_no”, ‘关键字’])topic_groups_dictdf 搜索上述目的组显示在他们里面的关键字的一个很好的近似,东西可以实现SEO专家。虽然我们只使用了一小组关键字,但是,虽然我们只使用了一小组关键字,但该方法明显可以缩放到数千(如果不是更多)。激活输出到更好地进行搜索 当然,可以进一步使用神经网络处理排名内容以获得更准确的集群和群集组命名,因为一些商业产品已经做到了。 现在,使用此输出,您可以:将其合并到您自己的SEO仪表板系统中以使您的趋势S和 SEO报告更有意义.Build通过通过搜索更高质量得分的意图来构建Google ADS账户来制造Google搜索活动 .Merge冗余面部电子商务搜索URL.Structure a购物网站根据搜索意图而不是典型产品目录的分类。我确定我还没有提到的更多应用程序 – 请随时对我尚未提及的任何重要的应用程序进行评论。[在任何情况下,您的SEO关键词研究只需更具可扩展,准确,准确,更快! 更多资源: 技术SEO的Python 如何使用Python分析SEO数据:参考指南 高级技术SEO:a完全指南 图像积分 精选图像: Astibuag / Shutterstock.com 作者的所有屏幕截图,7月2021年7月 广告Continue读数
